

こんにちは!しゅんです!
今回はゲームジャンルとゲーム会社の関係を分析していきます!
ゲーム会社とゲームジャンルにはどのような関係があるのでしょうか。今回はクロス集計表を使ってジャンルごとにゲーム会社の売上シェアを調べてみたいと思います。
また今回はpythonを使って分析をしていくのでコードも解説していこうと思います。
それでは解説していきましょう!
※この記事はvgsalesというデータから分かることにのみ注目して解説します。
そのためゲームの操作性やグラフィックなどのデータからわからないことには言及しません。
普段はNBAのデータ分析をしたりしています。
ぜひこちらの記事も読んでみてください!
このブログの簡単な紹介はこちらに書いてあります。
興味があったら見てみてください。
このブログでは経営工学を勉強している現役理系大学生が、経営工学に関することを色々話していきます!
ぼくが経営工学を勉強している中で感じたことや、興味深かったことを皆さんと共有出来たら良いなと思っています。
そもそも経営工学とは何なのでしょうか。Wikipediaによると
経営工学(けいえいこうがく、英: engineering management)は、人・材料・装置・情報・エネルギーを総合したシステムの設計・改善・確立に関する活動である。そのシステムから得られる結果を明示し、予測し、評価するために、工学的な分析・設計の原理・方法とともに、数学、物理および社会科学の専門知識と経験を利用する。
引用元 : 経営工学 – Wikipedia
長々と書いてありますが、要は経営、経済の課題を理系的な観点から解決する学問です。
データの入手
今回分析に用いるデータはkaggleというサイトからダウンロードできるvgsales.csvというファイルです。kaggleとは世界最大のデータ分析コンペサイトで、様々なデータを使って分析をすることができます。
今回使うデータはこちらからダウンロードできます。(無料の事前登録が必要)
vgsalesは1985年~2020年の間に発売されたゲームの中から10万本以上売れた16598個のゲームのデータが入っています。
データの項目は以下の図のようにRk(売上順位), Name, Platform, Year, Genre, Publisher, NA_Sales(北米), EU_Sales(ヨーロッパ), JP_Sales(日本), Other_Sales(その他), Global_sales(全世界)となっています。
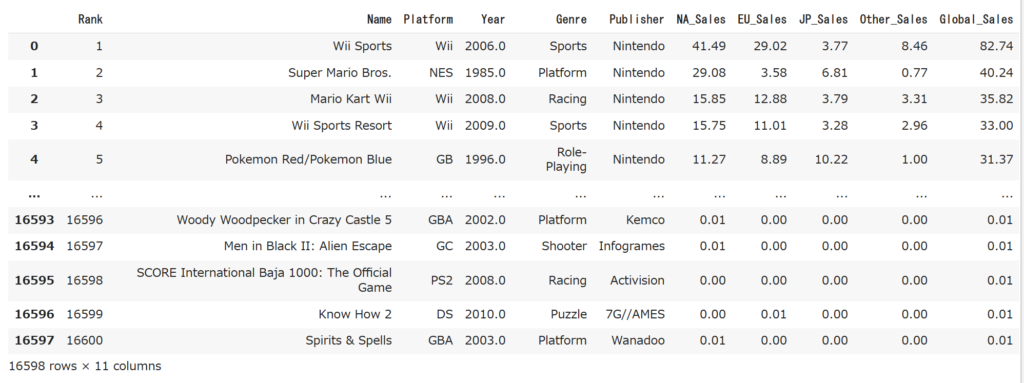
これを見ると1位から5位まで任天堂が独占していますね。これを見ただけでも任天堂がゲーム業界の覇権を握っていることが分かりますね。
この記事では上のデータを使ってより詳細な分析をしていきたいと思います。それでは実際に分析を始めていきましょう!
ゲーム会社とジャンルの関係を分析してみる
今回は以下の手順で分析を進めてみたいと思います。
分析に必要なライブラリのインポートやデータの前処理を行います。
ゲームの売上全体のトレンドを見てみます。
ゲーム売上が5億ドルを超えた2006年~2011年のデータだけを使ってジャンルとゲーム会社のクロス集計表を作成してみたいと思います
全ての年のデータを使って同じようにクロス集計表を作成してみたいと思います
それではSTEP. 1から1つずつ解説していきましょう!
STEP.1 事前準備
まずは分析に必要なライブラリをインポートしましょう。
# pandas, matplotlib, seabornをインポート
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as snsこれらはデータ分析をする上で必要な様々なことをやってくれる便利ツールだと思ってください。簡単に説明するとpandasはエクセルみたいな表データを扱うことができ、matplotlibとseabornはグラフや表といったデータの可視化ができるライブラリです。
asの後ろに書いてあるのは省略形です。これ以降pandasを使いたいときはpdと書けば良いです。matplotlibとseabornも同じように省略して使いたいと思います。
それではpandasを使ってvgsales.csvを読み込みましょう。
# vgsales.csvをdfという名前で読み込む
df = pd.read_csv("data/vgsales.csv")dfの中身を見てみましょう。
# dfを表示
df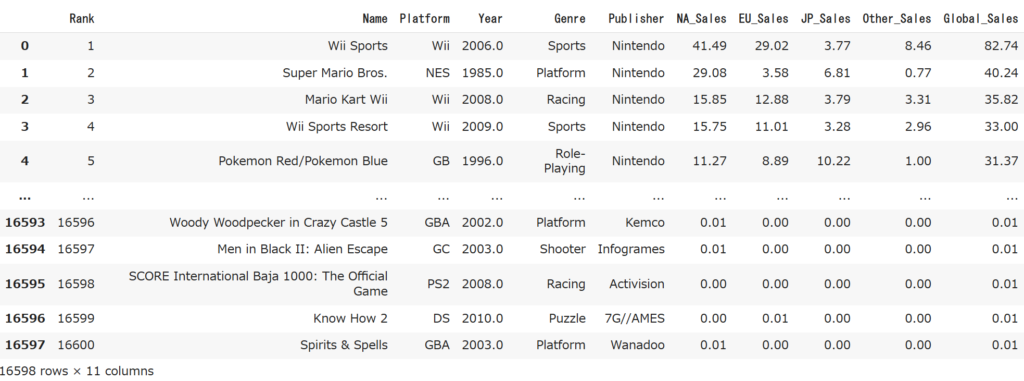
vgsales.csvは左から順に売上順位、ゲーム名、ゲーム機器、発売年、ジャンル、北米売上、ヨーロッパ売上、日本売上、他国売上、世界売上の項目があります。売上の単位はmillion$(100万ドル)です。
一番上にあるのは2006年に発売されたWii Sportsで、全世界で8274万ドルも売り上げていますね。4月2日のドル円換算で約110億円も売り上げています。

引用元 : https://www.nintendo.co.jp/wii/rspj/
それでは次にデータの前処理をやっていきます。欠損値が存在するか確認してみましょう。
# 欠損値の有無を確認する
print(df.isnull().sum())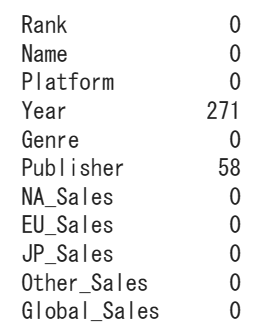
それぞれYearに271個、Publisherに58個欠損があるようです。欠損値があるデータを見てみましょう。
# 欠損値を含む行を抽出
result = df[df.isnull().any(axis=1)]
# 結果を表示(上位10番目まで)
result[:10]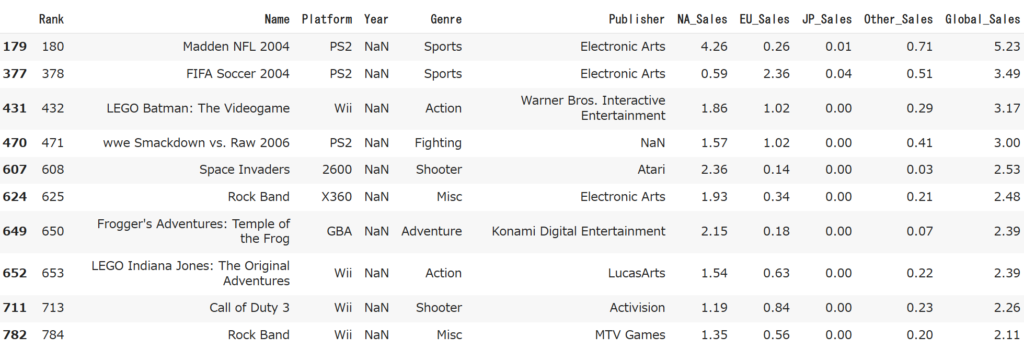
後で説明しますが今回の分析に用いるデータは「売上ランキングTOP100」のデータと「2006年~2011年における売上ランキングTOP100」のデータです。そしてこれらのデータには上記の欠損値を含むデータが入っていないので、今回欠損値がある行は削除してしまいます。
# 欠損値を削除
df.dropna(inplace=True)ということでここまでで事前準備が終わったので実際に分析に移っていきましょう。
STEP.2 売上の年推移をグラフにする
それでは次にその年に発売されたゲームの総売上を発売年ごとにプロットしたグラフを作成して、ゲーム業界のトレンドを見てみましょう。
# 発売年ごとに世界売上を合計してまとめる
global_sales_by_year = df.groupby('Year')['Global_Sales'].sum()
# グラフのサイズを決定
plt.figure(figsize = (15,4))
# 折れ線グラフを作成(横軸がyear, 縦軸が総売上)
plt.plot(global_sales_by_year.index, global_sales_by_year.values, marker = "o")
plt.title('Global Sales by Year') # タイトルを設定
plt.xlabel('Year') # x軸のラベルを設定
plt.ylabel('Global Sales (millions)') # y軸のラベルを設定
# グラフを表示
plt.show() 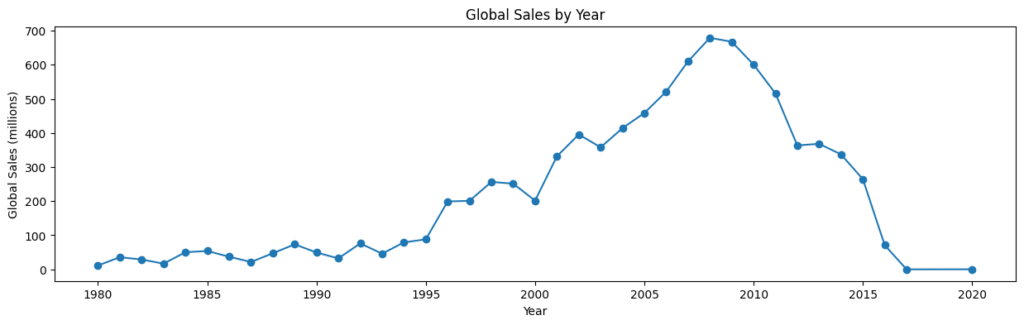
ということでゲーム売上の年推移をグラフにしてみました。これを見ると2000年代以降急激に売り上げが伸びているのが分かりますね。ピークは2000年代後半になっており、そこから段々と減少しているようです。
このデータは2017年のものなので、2010年代以降の売上が低いのは理解できますが、それでも著しく減少しているのが分かりますね。
いくつかの理由があると思いますが、個人的には2010年代からのスマートフォンの普及が大きな理由であると考えられます。
vgsales.csvにはビデオゲームのデータしか載っていないのでスマホゲームはおそらく含まれていません。そのため2010年代以降売上ががくっと落ちているのだと考えられます。
次に先ほどのグラフに5億ドルの線を引いてみましょう。
# 発売年ごとに世界売上を合計してまとめる
global_sales_by_year = df.groupby('Year')['Global_Sales'].sum()
# グラフのサイズを決定
plt.figure(figsize = (15,4))
# 5億ドルの線を引く
plt.hlines(500,1980, 2020, color = "red", ls = ":")
# 折れ線グラフを作成(横軸がyear, 縦軸が総売上)
plt.plot(global_sales_by_year.index, global_sales_by_year.values, marker = "o")
plt.title('Global Sales by Year') # タイトルを設定
plt.xlabel('Year') # x軸のラベルを設定
plt.ylabel('Global Sales (millions)') # y軸のラベルを設定
# グラフを表示
plt.show() 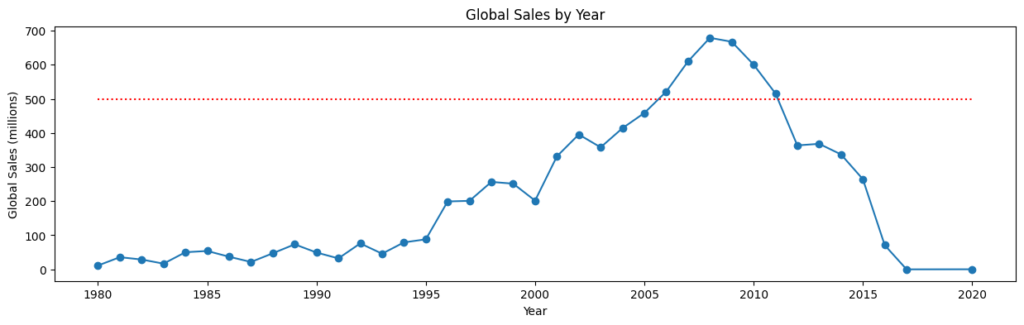
これを見ると2006年から2011年が5億ドルを超えている年になります。この6年間はメガヒットしたゲームが多いことが考えられます。ということでここからはすべての年を対象にした分析と2006年~2011年を対象にした分析の2つをやっていきたいと思います。
STEP.3では2006年~2011年におけるゲーム会社とゲームジャンルの分析、STEP.4では全ての年におけるゲーム会社とゲームジャンルの分析を行いたいと思います。
STEP.3 2006年~2011年のデータを分析する
まずは発売年が2006年から2011年のものだけを抽出しましょう。データ数が多いとゲーム会社が大量に出てきて分析しづらくなるため、世界売上が上位100位までのデータを抽出します。
# 2006年~2011年の売上上位100位までのデータを抽出
df_06_11 = df.query('Year >= 2006 and Year <= 2011')[:100]それではGenre(ジャンル)とPublisher(ゲーム会社)を使ってクロス集計表を作成します。最初にプログラムと表を見せた後に、どのように表を見るのかを説明します。
# クロス集計してDataFrameを作成
df_pivot = pd.pivot_table(df_06_11, values='Global_Sales', index="Genre", columns="Publisher", aggfunc=sum, fill_value=0)
# 行ごとの合計を計算
row_sum = df_pivot.sum(axis=1)
# 行ごとに割合を計算
df_pivot_perc = df_pivot.div(row_sum, axis=0) * 100
# ヒートマップの作成
plt.figure(figsize=(10, 6))
sns.heatmap(df_pivot_perc, cmap="Blues", annot=True, fmt='.1f', cbar=True)
plt.title('Global Sales by Genre and Year (%)')
plt.show()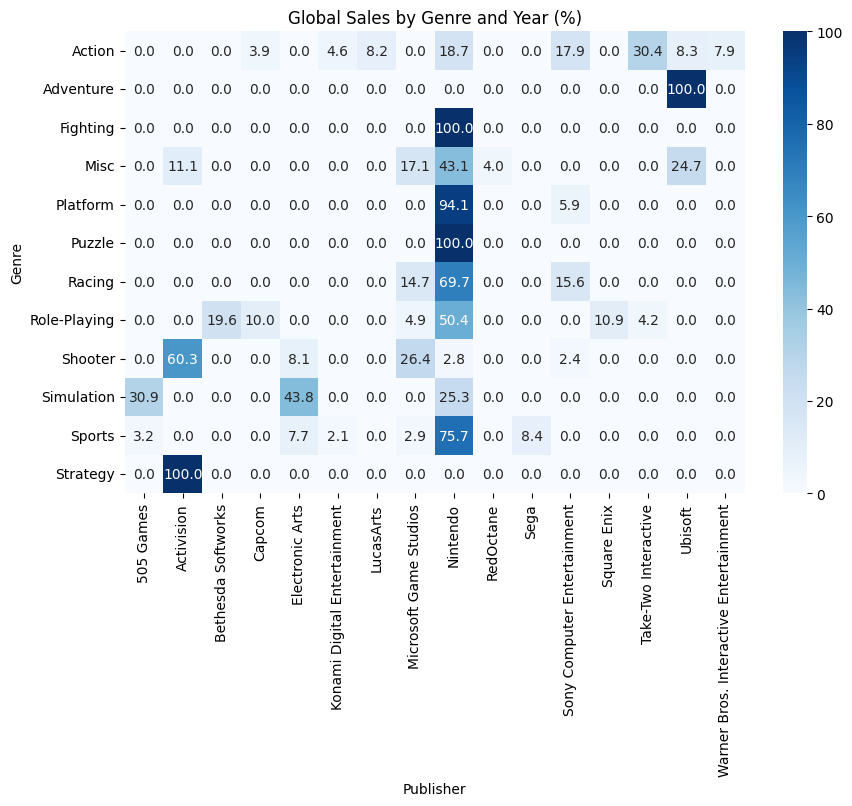
ということで横軸がゲーム会社、縦軸がジャンルのクロス集計表ができました。この表の見方を説明します。
まずこの表は%表記になっています。この数値は横一行を足したら100になるように設定されており、そのジャンルにおける各ゲーム会社の売上が何%かを表しています。
例えばActionの行を見てみるとNintendoが18.7となっています。これは「2006年~2011年に発売されたアクションゲームの中で、任天堂が発売したゲームが全てのアクションゲームのうち18.7%の売上を占めている」ということを表しています。
他にもFightingの行を見てみるとNintendoが100になっていますが、これは「2006年~2011年に発売された格闘ゲームは任天堂が発売したものが売上の100%を占めている」ということを表しています。
このことを踏まえて表を見てみると、ほとんどのジャンルで任天堂が圧倒的シェア率を誇っていますね。50%以上のシェア率を誇っているジャンルが6つ、そしてFightingとPuzzleに関してはシェア率100%です。
この表を見るといかに任天堂がゲーム業界の覇権を握っていたかが分かりますね。一体任天堂はどんなゲームを発売していたのでしょうか。代表してFightingとPuzzleのゲームを見てみましょう。
# GenreがFightingのデータを表示
df_06_11[df_06_11["Genre"] == "Fighting"]# GenreがPuzzleのデータを表示
df_06_11[df_06_11["Genre"] == "Puzzle"]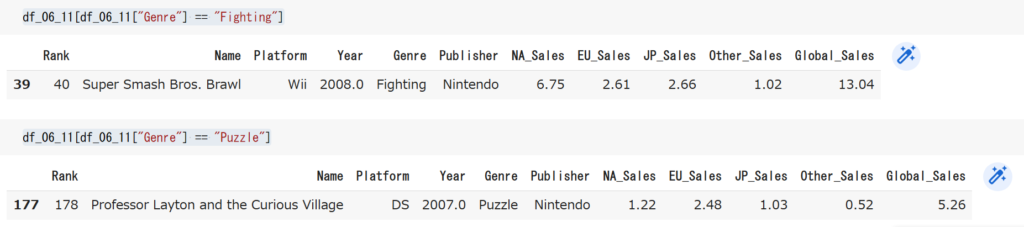


調べてみたらスマブラとレイトン教授でした。どちらも非常に有名なゲームですね。逆に2006年~2011年の間に発売されたアクションゲームとパズルゲームで10万本以上売れたのってこの2つしかないんですね。さすが任天堂です。
次に縦方向に%表記した表も作ってみましょう。
# クロス集計してDataFrameを作成
df_pivot = pd.pivot_table(df_06_11, values='Global_Sales', index="Genre", columns="Publisher", aggfunc=sum, fill_value=0)
# 列ごとの合計を計算
col_sum = df_pivot.sum(axis=0)
# 列ごとに割合を計算
df_pivot_perc = df_pivot / col_sum * 100
# ヒートマップの作成
plt.figure(figsize=(12, 6))
sns.heatmap(df_pivot_perc, cmap="Blues", annot=True, fmt='.1f', cbar=True)
plt.title('Global Sales by Genre and Year (%)')
plt.show()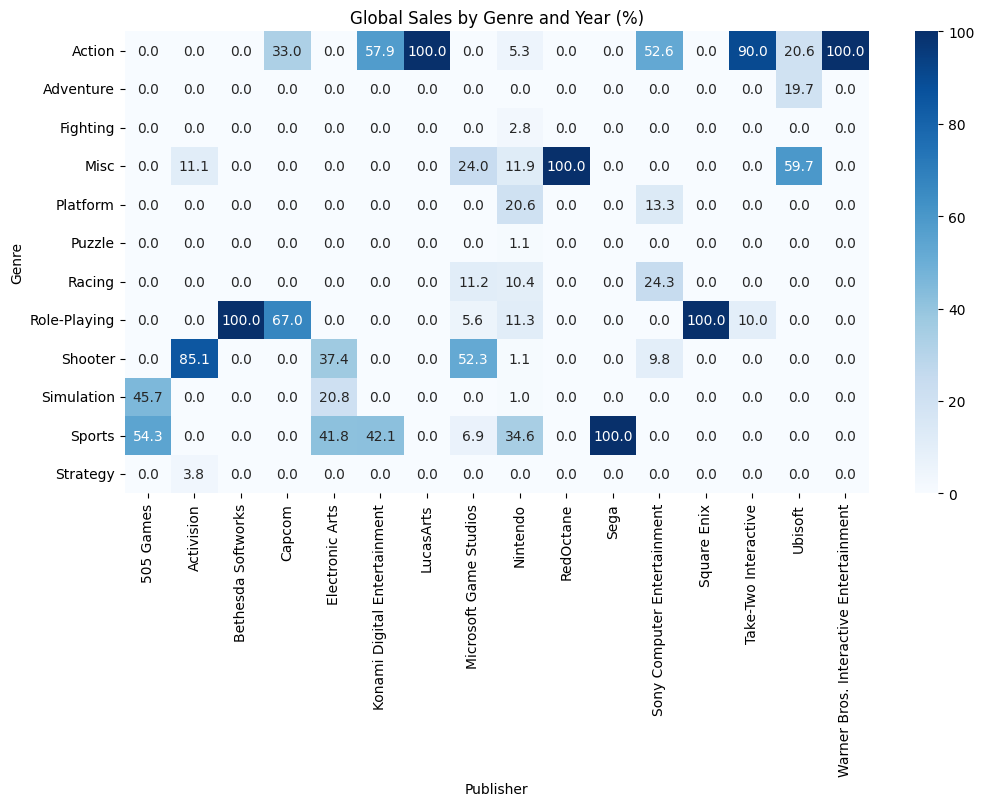
これは先ほどとは逆に、縦方向に足していったら100%になるように集計した表です。
例えばCapcomの列を見てみるとActionが33.0、Role-Playingが67.0となっています。これは「2006年~2011年にCapcomが発売したゲームで売上TOP100に入っているゲームジャンルの割合が、Actionが33%でRole-Playingが67%である」ということを表しています。
他にもSegaの列を見てみるとSportsが100になっていますが、これは「2006年~2011年にSegaが発売したゲームの中で売上TOP100に入っているゲームジャンルはSportsだけである」ということを表しています。
この表を見てもやはり目を引くのは任天堂です。任天堂の列を見てみるとほぼすべてのジャンルでTOP100の売上を出しているゲームを発売しているということが分かります。
つまり任天堂は様々なジャンルのゲームを大ヒットさせているということです。その中でも特に割合を占めているのがSportsで34.6%を占めていますね。どんなゲームが発売されたのでしょうか。
# ジャンルがSportsのデータだけ抽出
df_06_11[df_06_11["Genre"] == "Sports"]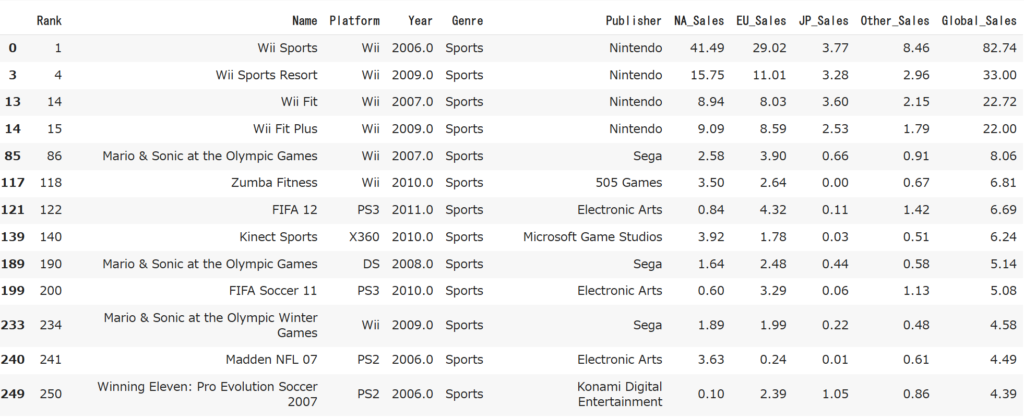




2006年~2011年に発売されたスポーツゲームのTOP4が全て任天堂です。どれも非常に有名なゲームです。僕もWii Sports ResortとWii Fitを持っていました。Global_Salesを見てもこの4つ(特にWii Sports)が飛びぬけていますね。
続きものが多いとはいえたった6年間でここまでメガヒットを連発する任天堂はやはりさすがですね。
※df_06_11は売上上位100本のデータしか扱っていないことに注意してください。すべてのデータを含めたらおそらくもっと数字は分散されるはずですが、下位のゲームになるほど売上が少ないので今回の分析結果とあまり変わらないと思います。
それでは最後に全ての年における売上TOP100のデータを分析してみましょう。
STEP.4 全ての年のデータを分析する
やることはSTEP.3と同じなので説明は省略してコードと結果の考察だけやります。
まずは行方向の%集計表からです。
# クロス集計してDataFrameを作成
df_pivot = pd.pivot_table(df[:100], values='Global_Sales', index="Genre", columns="Publisher", aggfunc=sum, fill_value=0)
# 行ごとの合計を計算
row_sum = df_pivot.sum(axis=1)
# 行ごとに割合を計算
df_pivot_perc = df_pivot.div(row_sum, axis=0) * 100
# ヒートマップの作成
plt.figure(figsize=(10, 6))
sns.heatmap(df_pivot_perc, cmap="Blues", annot=True, fmt='.1f', cbar=True)
plt.title('Global Sales by Genre and Year (%)')
plt.show()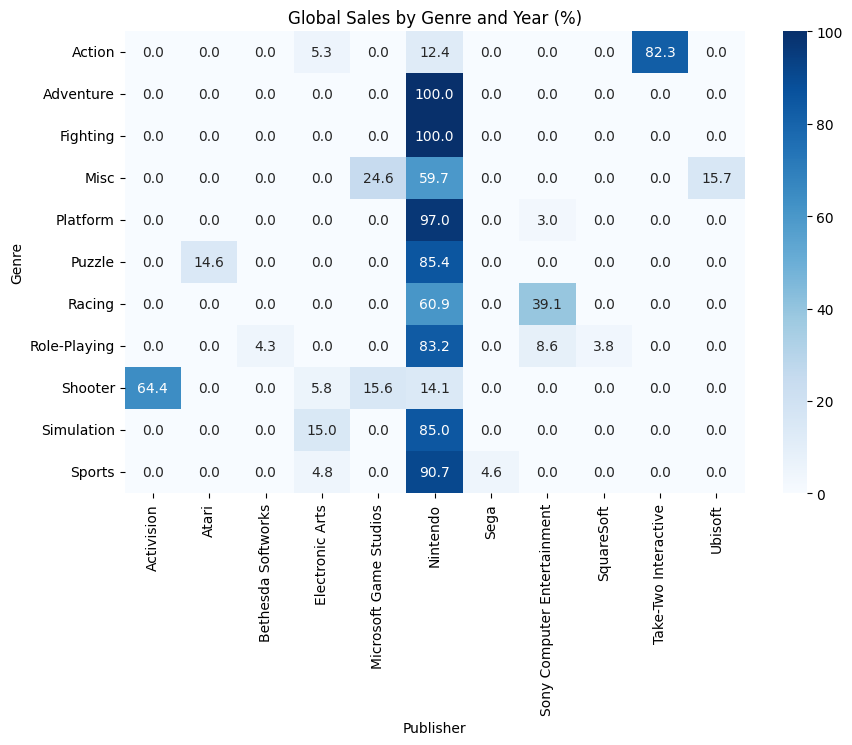
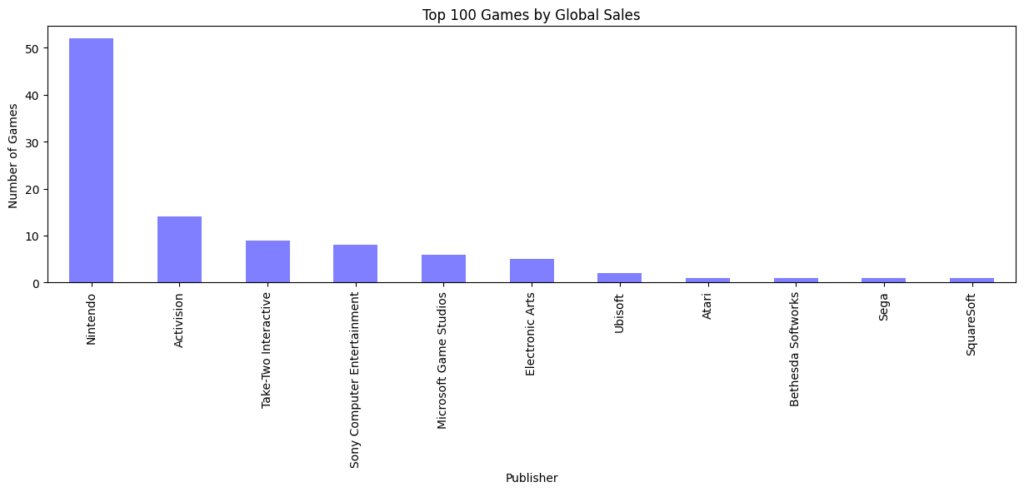
すべての年を含めた方がより任天堂の異常さが際立ちますね。50%以上のシェア率を誇るジャンルが9つ、100%のシェア率を誇るジャンルが2つです。
つまりこれまで発売されたゲームのうち売上TOP100のゲームはほぼ任天堂から発売されているということです。
調べてみたら売上TOP100のうち52個が任天堂から発売されていました。下のグラフを見ると圧倒的です。
次に縦方向の%表記で集計した表を作成します。
# クロス集計してDataFrameを作成
df_pivot = pd.pivot_table(df[:100], values='Global_Sales', index="Genre", columns="Publisher", aggfunc=sum, fill_value=0)
# 列ごとの合計を計算
col_sum = df_pivot.sum(axis=0)
# 列ごとに割合を計算
df_pivot_perc = df_pivot / col_sum * 100
# ヒートマップの作成
plt.figure(figsize=(12, 6))
sns.heatmap(df_pivot_perc, cmap="Blues", annot=True, fmt='.1f', cbar=True)
plt.title('Global Sales by Genre and Year (%)')
plt.show()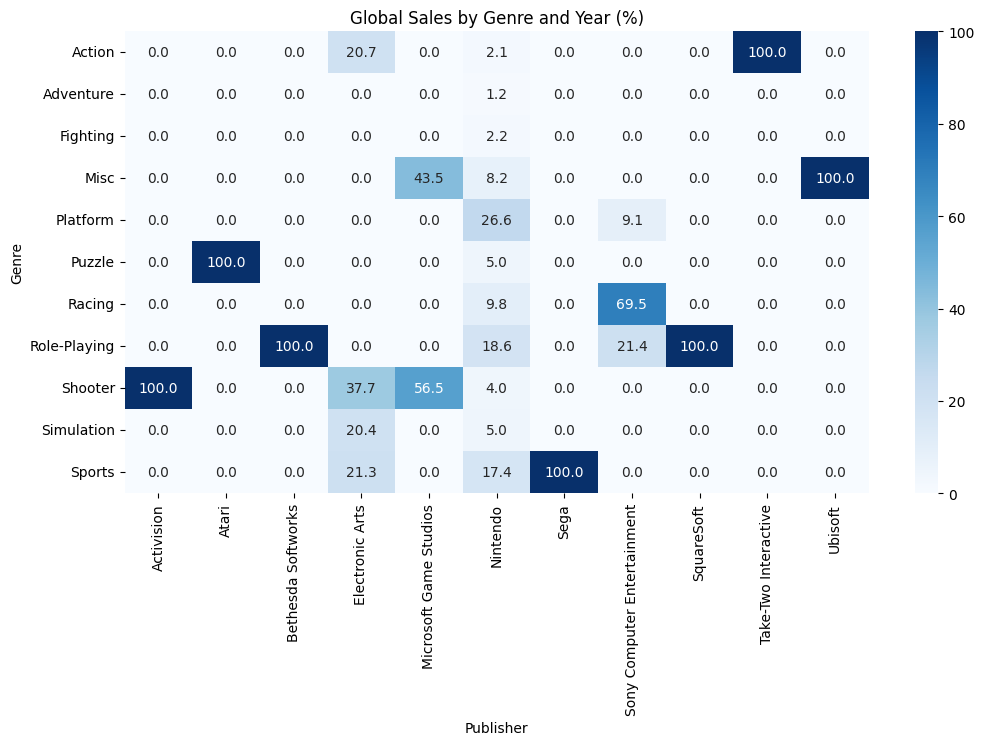
やはり任天堂が目立ちますね。すべてのジャンルでまんべんなく売上TOP100のゲームを発売していることが分かりますね。
2006年~2011年ではSportsが大きな割合を占めていましたが、全ての年で集計したらPlatformが26.6と最も大きな割合を占めています。
TOP100にランクインしているプラットフォームゲームを見てみましょう。
# 売上TOP100にランクインしているGenreがPlatformのデータを抽出
df[:100][df[:100]["Genre"] == "Platform"]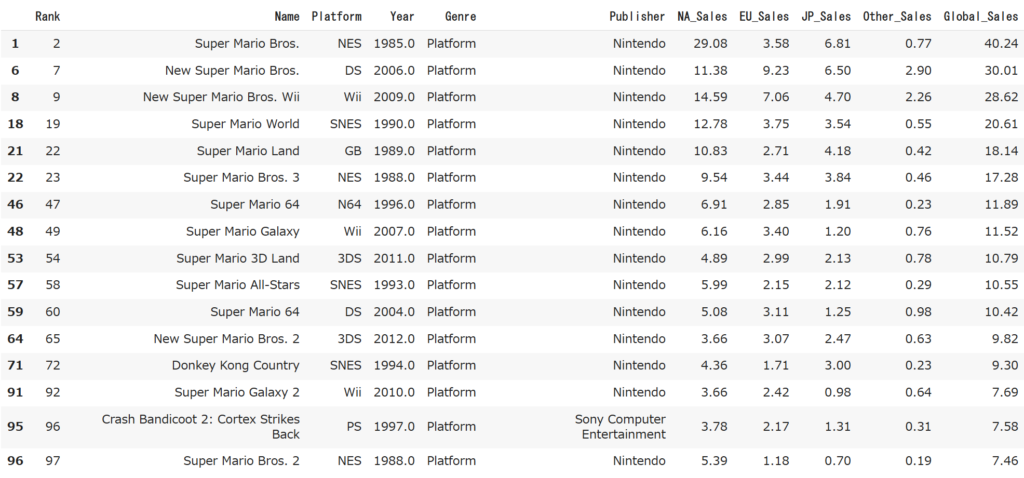
これを見るとマリオが独占していますね。



Yearの列を見ると1980年代から2010年代まで満遍なくランクインしていますね。30年以上もプレイされ続けるマリオと、それを生み出した任天堂のすごさが表れていますね。
おわりに
いかがでしたでしょうか。
今回の記事ではpythonを使ってゲーム会社とゲームジャンルについて説明していきました。結果的に任天堂のすごさを伝えるだけの記事になってしまいました笑
こんな感じでプログラミングを使えばいろいろなことができます。非常に興味深いですよね。
分析の対象となるデータを増やすとまた違う結果が得られるので興味がある人はぜひやってみてください!またその先の分析もぜひやってみてください!
これからもこのようにプログラミングで色々やっていきたいと思います。ぼくが一番勉強になるので続けていきたいです!
最後までこの記事を読んでくれてありがとうございました。

