


こんにちは!しゅんです!
今回の記事では色々なモデルで分類を試すことができるwebアプリをstreamlitで作ったから実際に使ってみます!
webアプリはこちらからアクセスできます!
それではやっていきましょう!
普段は統計検定2級の記事を書いてたりします。
ぜひ他の記事も読んでみてください!
このブログの簡単な紹介はこちらに書いてあります。
興味があったら見てみてください。
このブログでは経営工学を勉強している現役理系大学生が、経営工学に関することを色々話していきます!
ぼくが経営工学を勉強している中で感じたことや、興味深かったことを皆さんと共有出来たら良いなと思っています。
そもそも経営工学とは何なのでしょうか。Wikipediaによると
経営工学(けいえいこうがく、英: engineering management)は、人・材料・装置・情報・エネルギーを総合したシステムの設計・改善・確立に関する活動である。そのシステムから得られる結果を明示し、予測し、評価するために、工学的な分析・設計の原理・方法とともに、数学、物理および社会科学の専門知識と経験を利用する。
引用元 : 経営工学 – Wikipedia
長々と書いてありますが、要は経営、経済の課題を理系的な観点から解決する学問です。
webアプリを使ってみた
データを選択する
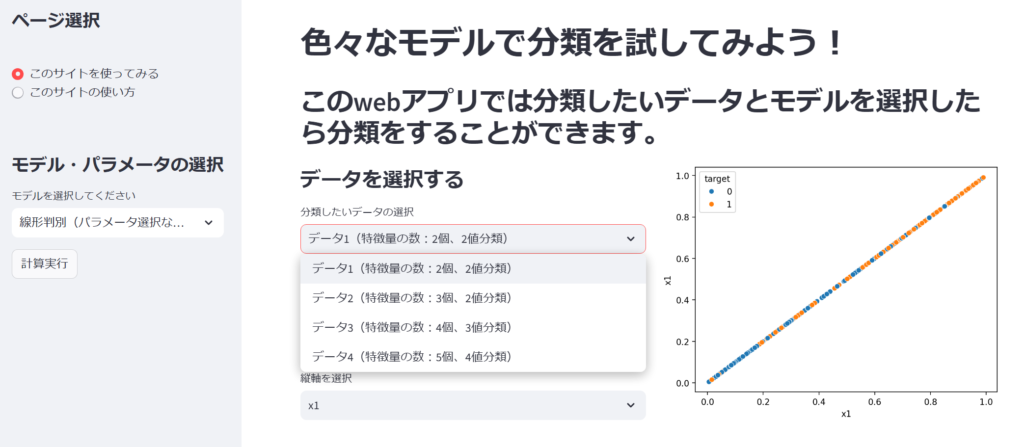
まずは分類したいデータを選択します。今回はデータ1からデータ4まで4つのデータを用意しました。各データの特徴量の数と目的変数の種類はそれぞれ
データ1 → 特徴量の数:2個、目的変数の種類:2個
データ2 → 特徴量の数:3個、目的変数の種類:2個
データ3 → 特徴量の数:4個、目的変数の種類:3個
データ4 → 特徴量の数:5個、目的変数の種類:4個
としています。
散布図でデータを可視化する
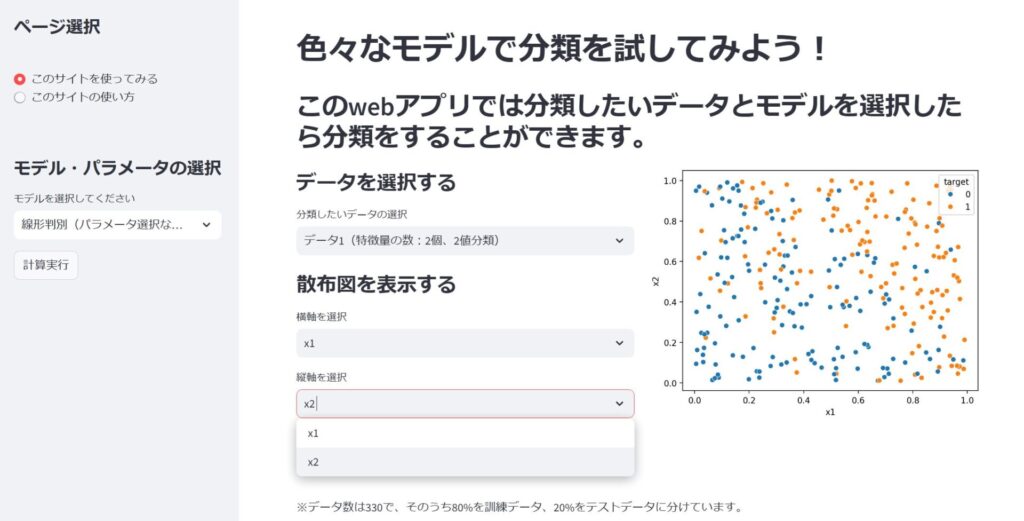
それでは次に散布図でデータを可視化してみましょう。横軸、縦軸を選択したら散布図が表示されます。上の例はデータ1を横軸が特徴量x1、縦軸が特徴量x2として散布図を描画しています。
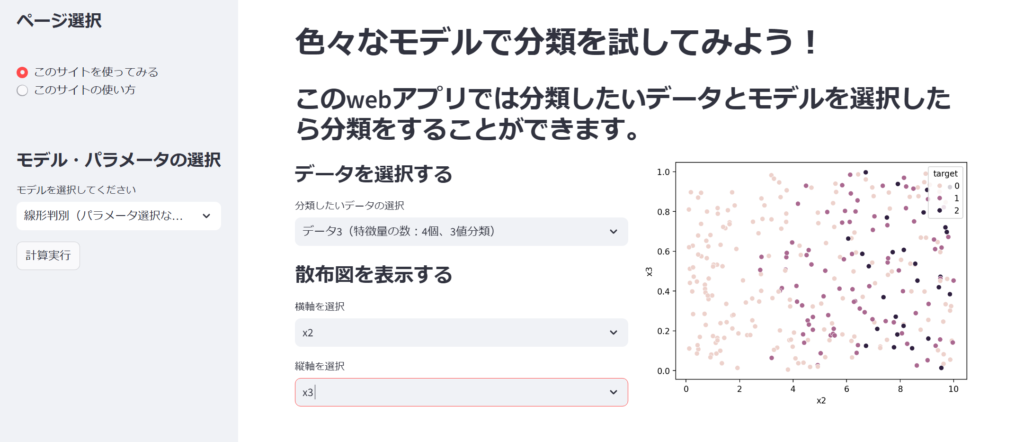
上の例はデータ3を横軸が特徴量x2、縦軸が特徴量x3として散布図を描画しています。
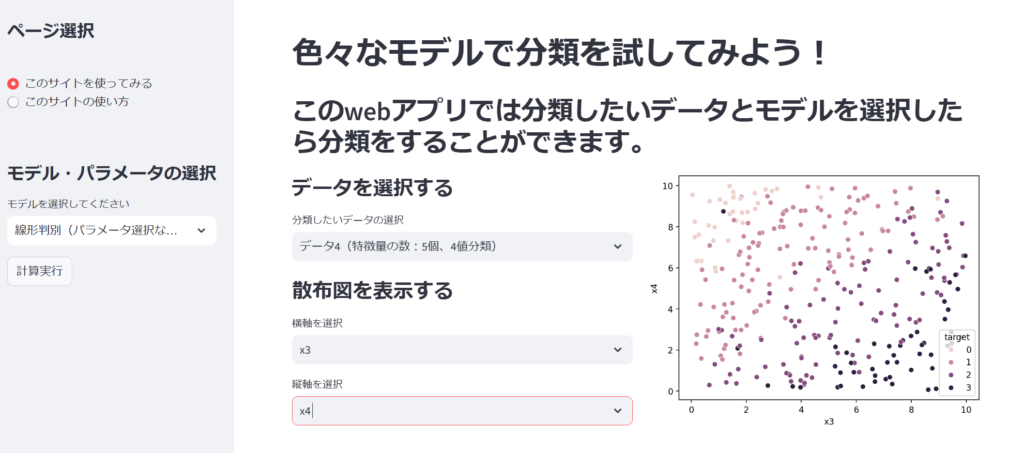
上の例はデータ4を横軸が特徴量x3、縦軸が特徴量x4として散布図を描画しています。
モデル・パラメータを選択する
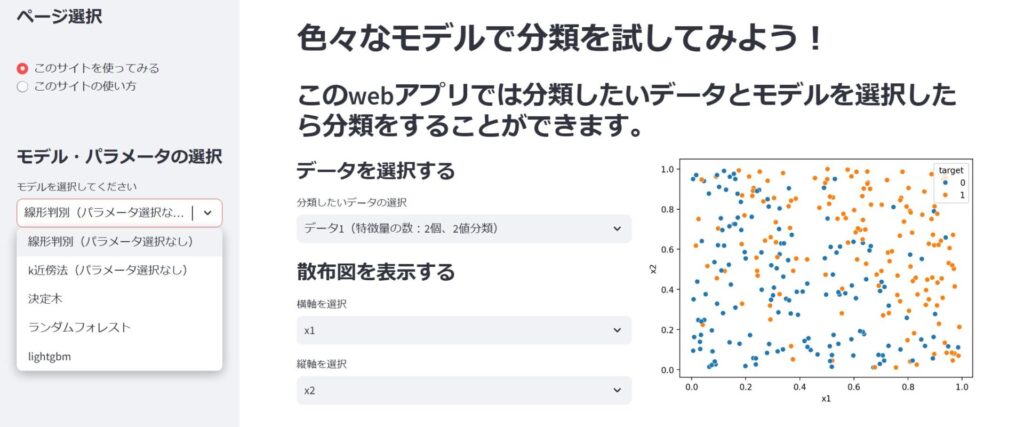
それでは次にモデル・パラメータを選択します。サイドバーにある「モデル・パラメータの選択」のところからモデルを選択します。モデルは線形判別、k近傍法、決定木、ランダムフォレスト、lightgbmの5つを用意しました。
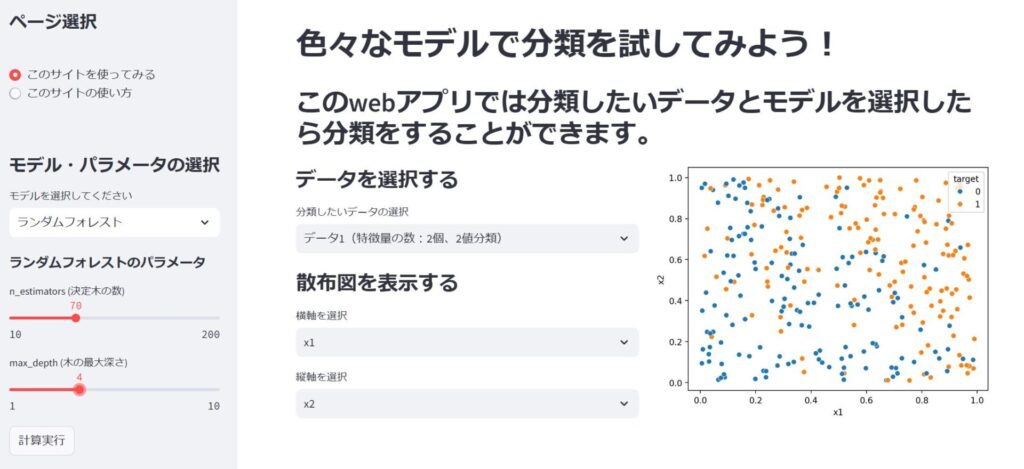
モデルを選択したら次はパラメータを選択しましょう。上の例はモデルとしてランダムフォレストを選択したときの図を表しています。
ランダムフォレストのパラメータとして、n_estimators(決定木の数)とmax_depth(木の最大深さ)を用意しました。ここを自分の好きな値に設定しましょう。
線形判別とk近傍法はパラメータ選択がありません。
計算を実行する
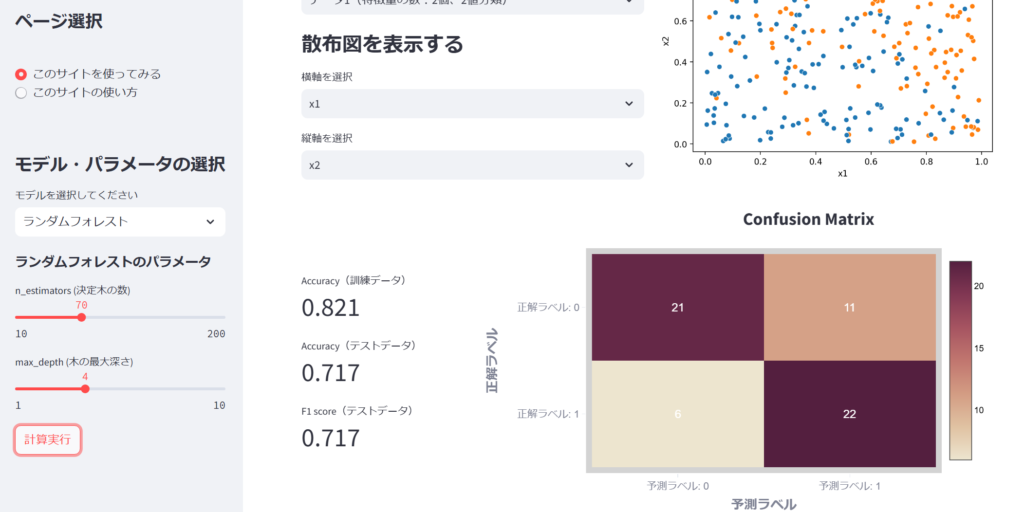
モデル・パラメータを選択したら「計算実行」ボタンを押します。計算を実行したら訓練データのAccuracy, テストデータのAccuracy, F1 score, Confusion Matrixの4つが表示されます。
Accuracy, F1 score, Confusion Matrixはこちらの記事で解説しています!
現在制作中
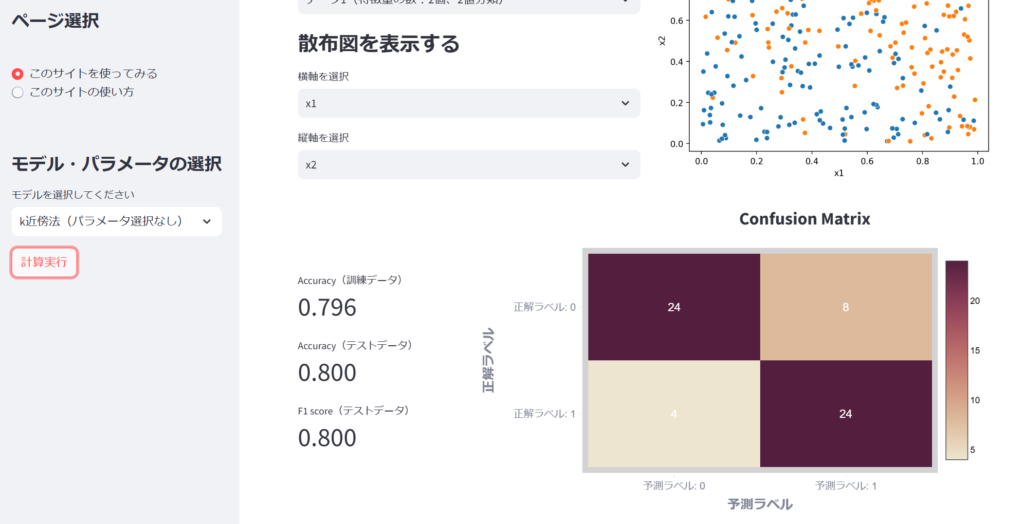
k近傍法でも分類してみました。ランダムフォレストよりもk近傍法の方が、AccuracyもF1 scoreも高いですね。
他のデータも分類してみましょう。
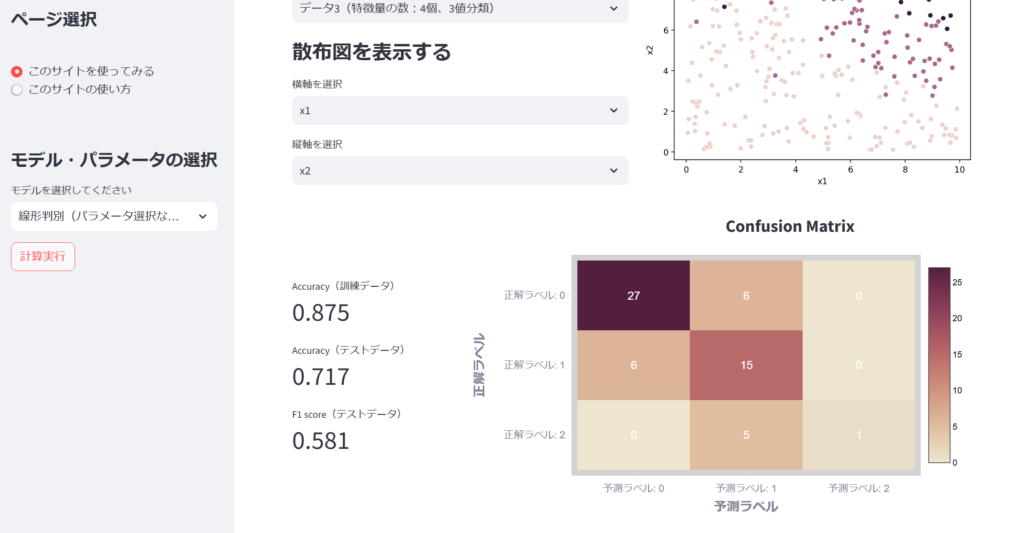
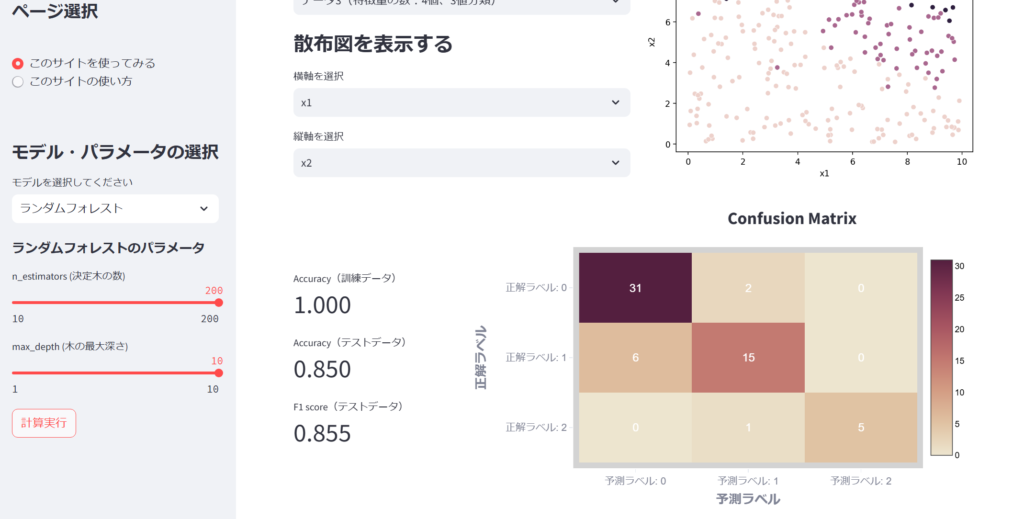
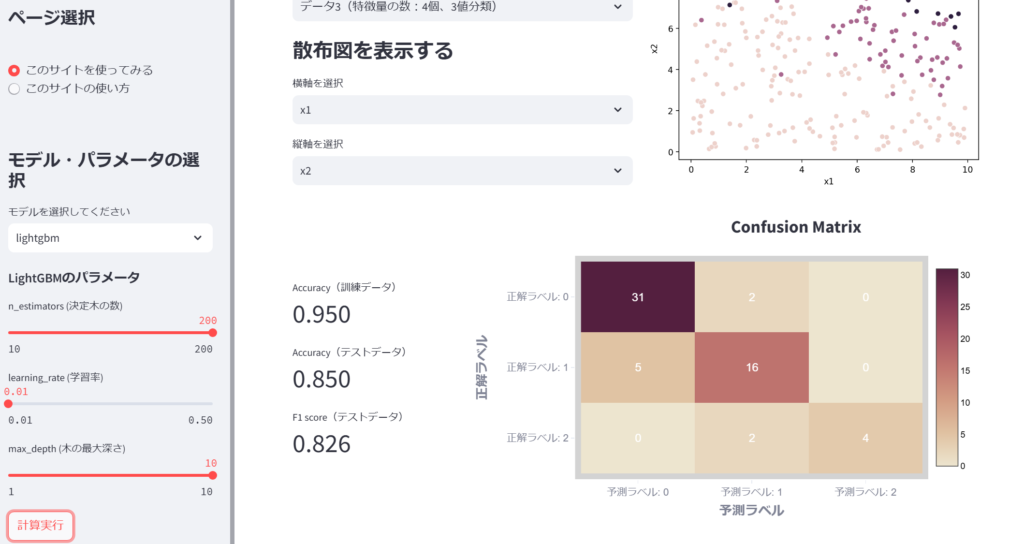
おわりに
いかがでしたか。
今回の記事では自分で作ったwebアプリを使ってみました。
今後もこのようなデータ分析に関する記事を書いていきます!
最後までこの記事を読んでくれてありがとうございました。

