


こんにちは!しゅんです!
いきなりですが皆さんはデータの標準化を知っていますか?
データの標準化は異なるデータを比較するのに使うとても重要な操作で、統計やデータ分析でよく使います。ぼくが最近統計検定の勉強をしていたときにでてきたので皆さんにもシェアしたいと思います!今回は説明と一緒にpythonを使ってどんなものか確かめたいと思います。
それでは解説していきましょう!
普段はNBAのデータ分析をしたりしています。ぜひこちらの記事も読んでみてください!
このブログでは経営工学を勉強している現役理系大学生が、経営工学に関することを色々話していきます!
ぼくが経営工学を勉強している中で感じたことや、興味深かったことを皆さんと共有出来たら良いなと思っています。
そもそも経営工学とは何なのでしょうか。Wikipediaによると
経営工学(けいえいこうがく、英: engineering management)は、人・材料・装置・情報・エネルギーを総合したシステムの設計・改善・確立に関する活動である。そのシステムから得られる結果を明示し、予測し、評価するために、工学的な分析・設計の原理・方法とともに、数学、物理および社会科学の専門知識と経験を利用する。
引用元 : 経営工学 – Wikipedia
長々と書いてありますが、要は経営、経済の課題を理系的な観点から解決する学問です。
データの標準化ってなに?
データの標準化を一言で説明すると
異なるデータを比較するために行う操作
のことを表します。例えば以下の例を見てみましょう。
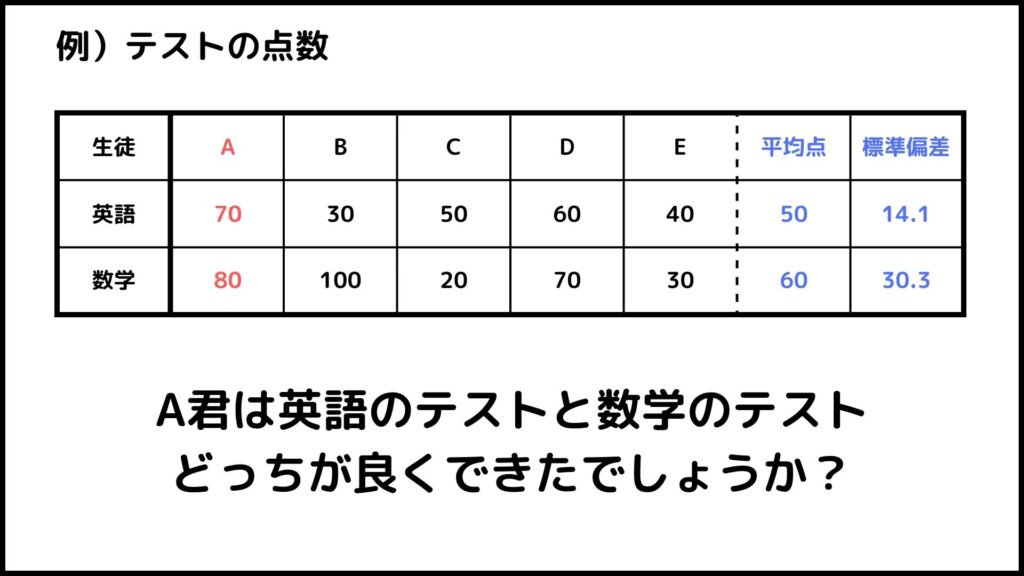
A君のテストの結果を見ると数学の点数の方が高いので一見すると良くできたのは数学のテストのような気がします。でも実はこれだけでは数学のテストの方が良くできたとは言えないんです。
なぜ言えないかというとそれは平均点と標準偏差が違うからです。
平均点については理解しやすいと思います。A君は数学のテストの方が英語のテストよりも10点高かったですが、同時に数学のテストの平均点も英語のテストより10点高いのでそのまま比較しても意味がないのです。
標準偏差はデータのばらつきを表す指標です。標準偏差が小さい程データは平均値に分布していることになります。下の図を見てください。
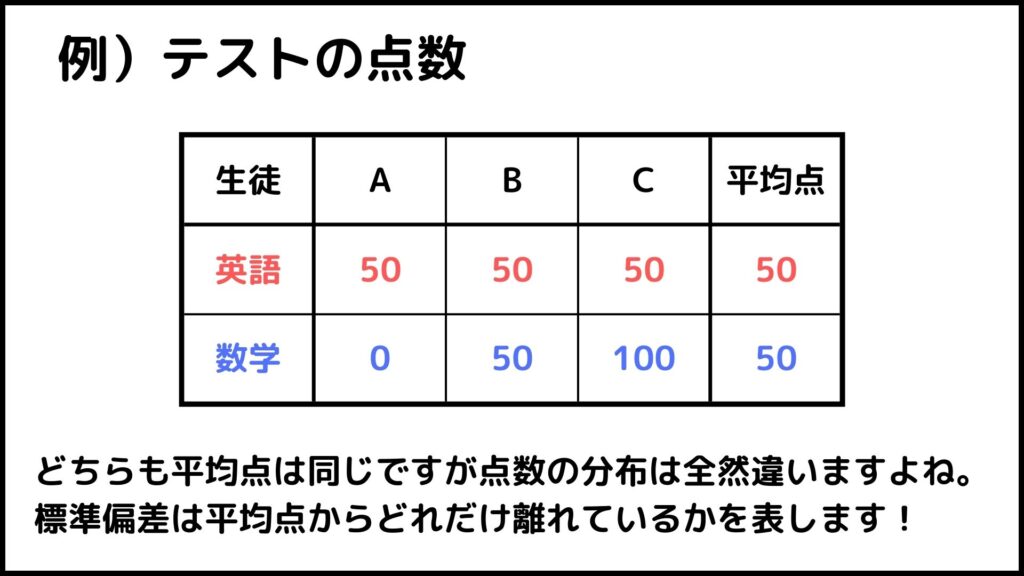
どちらのテストも平均点は同じ50点ですが点数の分布は全く違います。B君は両方のテストで50点を取っていますが、同じくらいできたとは言い難いです。このようなデータを比較するときに使う指標の1つが標準偏差です。
各生徒の英語の点数は全て平均点と同じ50点なので標準偏差は0になります。一方数学の点数はバラバラです。このような点数分布の標準偏差は大きくなります。
このように平均点が同じでも標準偏差が違うとうまく比較ができません。ではどうすれば良いのでしょうか。
これらを解決するのが標準化です。
データの標準化の公式
データの標準化の公式は、
(データ値 ー 平均値) / 標準偏差
です。これによって異なるデータを比較することができます。実際に最初のスライドのA君のデータ値を標準化してみましょう。
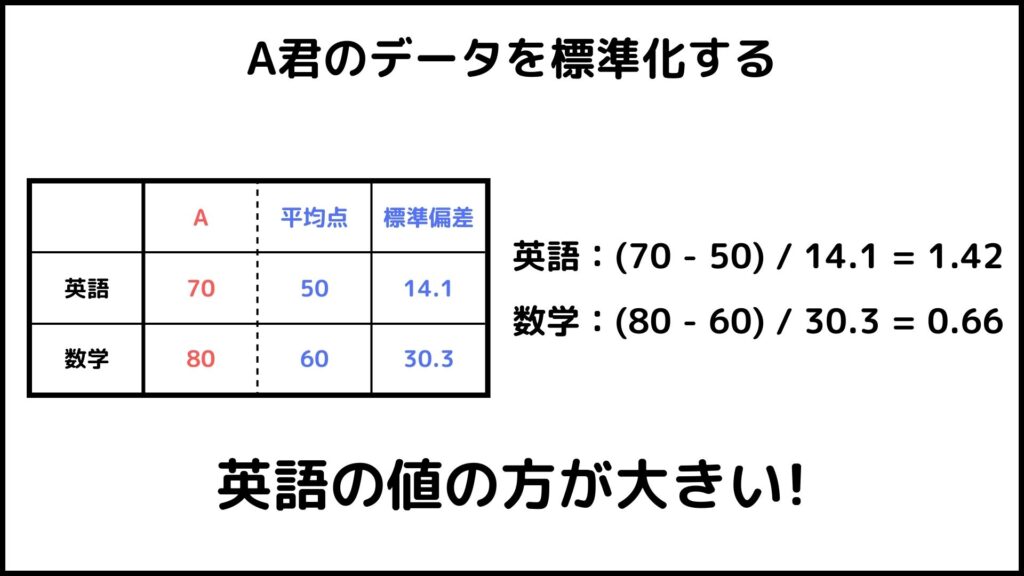
ということで標準化した後の点数は英語の方が高かったです。
それでは実際にpythonを使ってやってみましょう。
pythonでデータの標準化をやってみる
普通に計算する
計算しやすくするためにpandasとnumpyを使おうと思います。
# pandasをインポート
import pandas as pd
# numpyをインポート
import numpy as np次に一番初めのスライドのデータを作成します。
# テストのデータを作成する
df = pd.DataFrame([[70,80],[30,100],[50,20],[60,70],[40,30]],index = ["A","B","C","D","E"], columns = ["英語", "数学"])
# データを表示する
df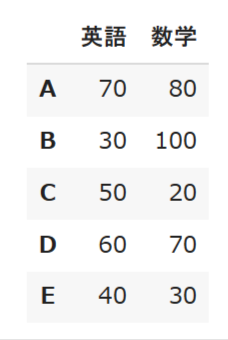
次に英語と数学のデータそれぞれで平均値と標準偏差を求めます。
# 英語の平均値を求める
mean_Eng = np.mean(df["英語"])
# 数学の平均値を求める
mean_Mat = np.mean(df["数学"])
# 英語の標準偏差を求める
std_Eng = np.std(df["英語"])
# 数学の標準偏差を求める
std_Mat = np.std(df["数学"])最後に標準化した点数を表示します。
# 英語のデータを標準化する
df_Standard_Eng = (df["英語"] - mean_Eng) / std_Eng
# 標準化した結果を表示
df_Standard_Eng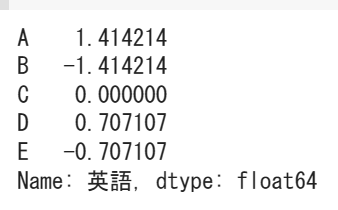
数学についてもやってみましょう。
# 数学のデータを標準化する
df_Standard_Mat = (df["数学"] - mean_Mat) / std_Mat
# 標準化した結果を表示
df_Standard_Mat
ということで全生徒の標準化した点数を求めることができました。それでは次にscikit-learnからStandardScalerを使って標準化をしてみようと思います。
scikit-learnを使って計算する
# StandardScalerをインポート
from sklearn.preprocessing import StandardScaler
# データを標準化する
scaler = StandardScaler()
scaler.fit(df)
standard = scaler.transform(df)
# 標準化した点数を表示
standard
左列が英語で右列が数学です。scikit-learnを使えばこんな感じですぐに標準化ができます!
偏差値ってなに?
テストの成績を評価する方法と言えば偏差値ですよね。実は偏差値はこの標準化点数を使って求めているんです!
偏差値の公式は以下のようになります。
偏差値 = 標準化点数 × 10 + 50
ということで先ほど計算した標準化点数を10倍して50を足し算したら偏差値が出てくるんです。最後にpythonを使って実際に計算してみましょう。
# 英語の偏差値を求めて表示する
df_Standard_Eng * 10 + 50
数学についても計算してみましょう。
# 数学の偏差値を求めて表示する
df_Standard_Mat * 10 + 50
ということで偏差値の計算ができました。A君の偏差値を見ると英語の方が高いですね。元の点数は数学の方が高いにもかかわらず平均点や標準偏差が違うと結果は全然変わってきます!
おわりに
いかがでしたでしょうか。
今回の記事ではデータの標準化について説明していきました。実はこの標準化が偏差値の計算に用いられているのは非常に興味深いですよね。
これからもこのようなデータ分析について話していこうと思います。ぼくが一番勉強になるので続けていきたいです!
最後までこの記事を読んでくれてありがとうございました。
この記事が役に立ったら幸いです。

