


- ロジスティック回帰ってなに?
- ロジスティック回帰をpythonで実装したい…
こんにちは!しゅんです!
今回はロジスティック回帰について解説していきます!
この記事ではロジスティック回帰をpythonで実装する方法を解説します。前回の記事ではロジスティック回帰のアルゴリズムの解説をしました。

それではやっていきましょう!
本記事を書くにあたって、この書籍を使って勉強しました。
ロジスティック回帰ってなに?
ロジスティック回帰:
データが2つのグループのどっちに属すかを確率で表す手法
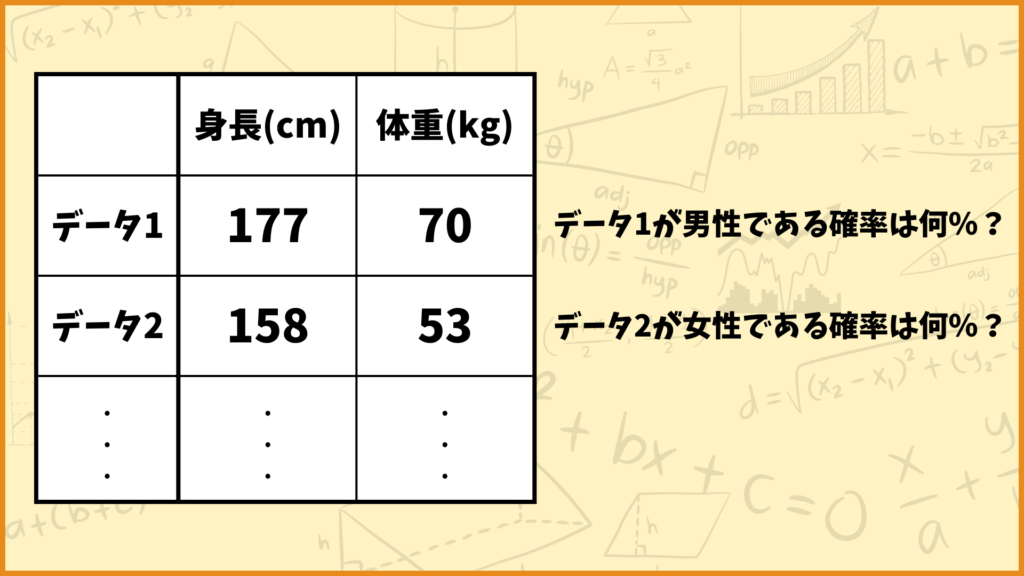
上図の例を見てみましょう。例えばデータ1は身長177cm、体重70kgというデータですが、これは男性のデータっぽいですね。一方でデータ2は身長158cm、体重53kgのデータですが、これは女性のデータっぽいですね。
ロジスティック回帰では与えられたデータがどれだけ男性っぽいか、どれだけ女性っぽいかを確率として出力します。データ1を入力したら90%という数字が出力されてデータ2を入力したら15%が出力されるようなイメージです。
ロジスティック回帰による予測結果はそのデータが男性である確率を表します。女性である確率は1から男性である確率を引き算すれば計算できます。今の例で言うとデータ1が女性である確率は10%、データ2が女性である確率は85%と計算できます。
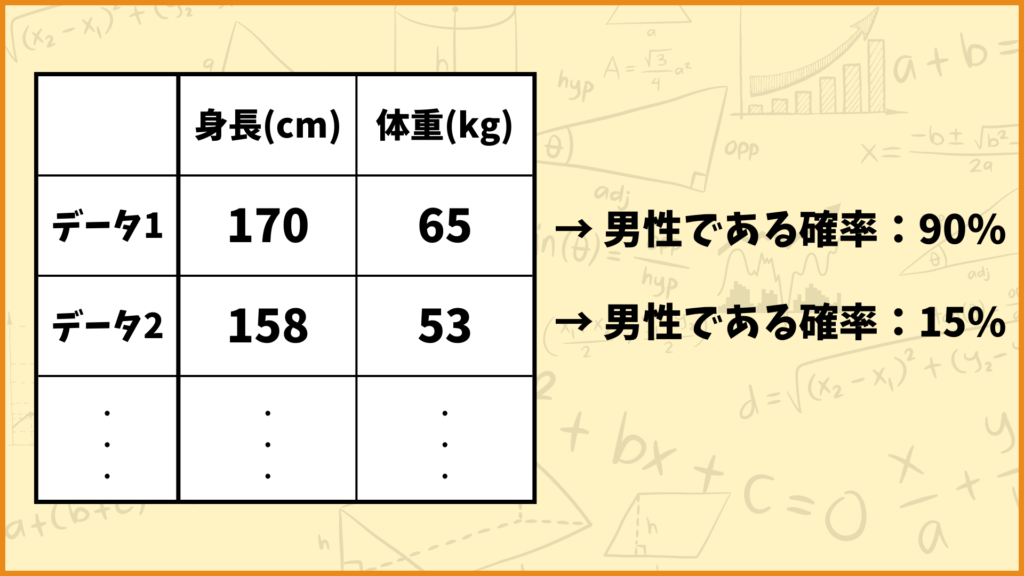
ロジスティック回帰は教師あり学習の1つです。すなわちそのデータが男性なのか女性なのかという正解のデータがある状態で学習を行います。
ロジスティック回帰をpythonで実装する
今回はiris datasetというデータセットを使ってロジスティック回帰を実行しようと思います。結論以下のpythonのコードを実行することでロジスティック回帰を実装することができます。
## 必要なライブラリのインポート
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.preprocessing import StandardScaler
## データセットの準備
iris = load_iris()
X = iris.data # 説明変数
y = iris.target # 目的変数
# データの標準化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# データを訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
## ロジスティック回帰による学習
model = LogisticRegression(max_iter=100) # 最大反復回数を設定
model.fit(X_train, y_train) # 訓練データを使って学習
y_pred = model.predict(X_test) # テストデータの予測
## 予測結果を表示
accuracy = accuracy_score(y_test, y_pred) # accuracyを計算
print(f"Accuracy: {accuracy}")
このコードを実行すると上の結果が得られました。それでは1つずつ解説していきます。
必要なライブラリのインポート
## 必要なライブラリのインポート
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.preprocessing import StandardScaler
ここでは必要なライブラリをインポートしています。
2行目ではload_irisをインポートしています。iris(アヤメ)データセットを読み込むための関数です。今回はこのirisデータセットを使ってロジスティック回帰を実装したいと思います。
3行目ではLogisticRegressionをインポートしています。pythonでロジスティック回帰を実行するために使います。
4行目ではtrain_test_splitをインポートしています。データを訓練データとテストデータに分割するために使います。
5行目ではaccuracy_scoreをインポートしています。予測結果のaccuracyを計算するために使います。
6行目ではStandardScalerをインポートしています。データの標準化を行うために使います。
データセットの準備
## データセットの準備
iris = load_iris()
X = iris.data # 説明変数
y = iris.target # 目的変数
# データの標準化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# データを訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
2行目でiris(アヤメ)データセットを取得しています。データセットの中身は下図のようになっています。
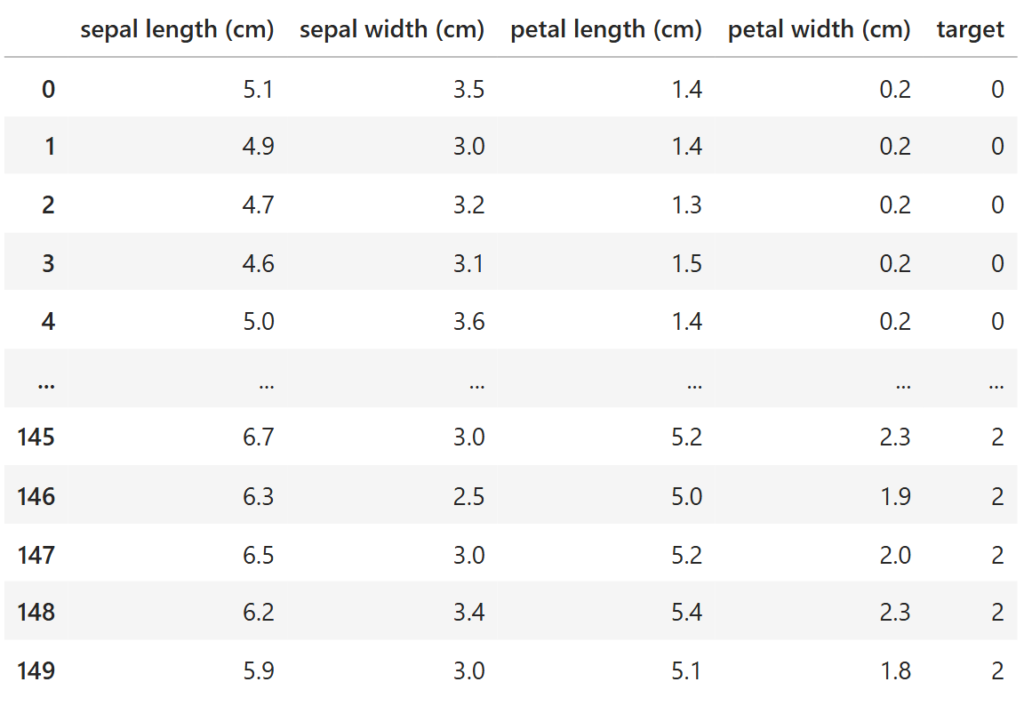
import pandas as pd
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['target'] = iris.target
df
irisデータセットは4つの説明変数と1つの目的変数で構成されています。目的変数は0,1,2のラベルのいずれかを取ります。
3行目ではirisデータセットから4つの説明変数だけを取得しています。名前は「X」です。
4行目ではirisデータセットから目的変数だけを取得しています。名前は「y」です。
6行目~7行目では説明変数を標準化しています。標準化したデータは「X_scaled」としています。
9行目ではデータを訓練データとテストデータに分割しています。引数の「test_size」はデータの何割をテストデータに割り当てるかを表しています。今回は全体の2割をテストデータに、残りの8割を訓練データに割り当てます。
各データの名前は下の表のようになっています。
| 説明変数 | 目的変数 | |
| 訓練データ | X_train | y_train |
| テストデータ | X_test | y_test |
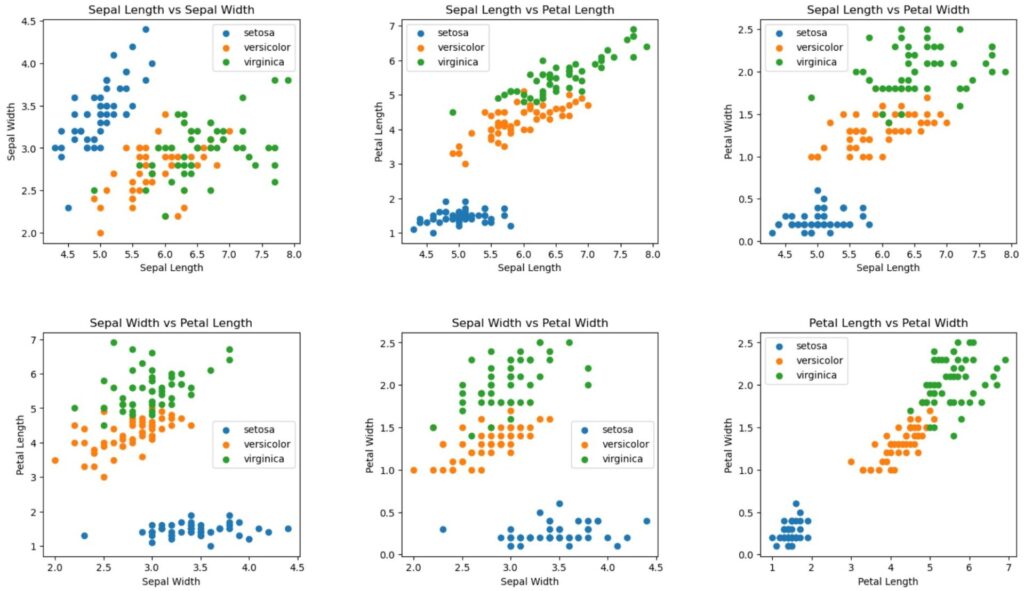
irisデータセットを可視化してみます。なお目的変数のラベルは
0:setosa
1:versicolor
2:virginica
をそれぞれ表しています。
import matplotlib.pyplot as plt
## 散布図の描画
features = ['Sepal Length', 'Sepal Width', 'Petal Length', 'Petal Width']
# 3x2のレイアウトで図を作成
fig, axes = plt.subplots(2, 3, figsize=(18, 10))
plt.subplots_adjust(wspace=0.4, hspace=0.4)
# 特徴量の組み合わせをループ処理
combination = 0
for i in range(len(features)-1):
for j in range(i+1, len(features)):
row = combination // 3
col = combination % 3
# 各クラスのデータをプロット
for k in range(len(iris.target_names)):
axes[row, col].scatter(X[y==k, i], X[y==k, j], label=iris.target_names[k])
axes[row, col].set_xlabel(features[i])
axes[row, col].set_ylabel(features[j])
axes[row, col].set_title(f'{features[i]} vs {features[j]}')
axes[row, col].legend()
combination += 1
plt.show()ロジスティック回帰による学習
## ロジスティック回帰による学習
model = LogisticRegression(max_iter=100) # 最大反復回数を設定
model.fit(X_train, y_train) # 訓練データを使って学習
y_pred = model.predict(X_test) # テストデータの予測
2行目でロジスティック回帰を行うための準備をしています。モデルには「model」という名前を付けました。括弧内の「max_iter」は最大反復回数を表しています。今回は100回としました。
3行目で実際にモデルを訓練しています。モデルには先ほど分割した訓練データの「X_train」と「y_train」を入力しています。
4行目では学習したモデルにテストデータの説明変数である「X_test」を入力してモデルの予測値を手に入れます。予測値には「y_pred」と名前を付けました。
「y_pred」は下図のようになっています。

予測結果を表示
## 予測結果を表示
accuracy = accuracy_score(y_test, y_pred) # accuracyを計算
print(f"Accuracy: {accuracy}")
2行目でaccoracyを計算しています。accuracyは予測値「y_pred」が実測値「y_test」とどれだけ一致しているかを表す指標です。例えば
y_pred = [0,0,1,1,2]
y_test = [0,0,1,2,2]
の場合、5個中4個一致しているのでaccuracyの値は
\((\text{accuracy}) = \frac{4}{5} = 0.8\)
と計算できます。
\\\ accuracyの詳しい説明はこちらから! ///

3行目でaccuracyを表示しています。結果は下図のようになっています。
これを見るとaccuracyの値が1となっていることが分かります。すなわち
「テストデータを100%正しく分類することができた」
と言うことを表しています。
おわりに
いかがでしたか。
今回の記事ではロジスティック回帰について解説しました。
今後もこのような機械学習に関する記事を書いていきます!
最後までこの記事を読んでくれてありがとうございました。
普段は組合せ最適化の記事を書いてたりします。
ぜひ他の記事も読んでみてください!
このブログの簡単な紹介はこちらに書いてあります。
興味があったら見てみてください。
このブログでは経営工学を勉強している現役理系大学生が、経営工学に関することを色々話していきます!
ぼくが経営工学を勉強している中で感じたことや、興味深かったことを皆さんと共有出来たら良いなと思っています。
そもそも経営工学とは何なのでしょうか。Wikipediaによると
経営工学(けいえいこうがく、英: engineering management)は、人・材料・装置・情報・エネルギーを総合したシステムの設計・改善・確立に関する活動である。そのシステムから得られる結果を明示し、予測し、評価するために、工学的な分析・設計の原理・方法とともに、数学、物理および社会科学の専門知識と経験を利用する。
引用元 : 経営工学 – Wikipedia
長々と書いてありますが、要は経営、経済の課題を理系的な観点から解決する学問です。
参考文献
