


- pydanticってなに?
- 実行不能になるけど原因が分からない…
- 入力データを安心して使いたい…
こんにちは!しゅんです!
実務で最適化問題を解くとき、想定外のエラーが出たり、ソルバーに「実行不能(Infeasible)」と言われたりして原因が分からず困ったことはありませんか?実はこうしたトラブルの背景には「入力データの不備」が隠れていることが意外と多いんです。
データの不備に気づけないと貴重な時間をかけて計算した後にエラーが判明し、データを修正してまた数時間の再計算……といった悲惨な事態を招きかねません。
そこで今回の記事では、こうした「計算のやり直し」を防ぐために、Pydanticを活用した入力データのバリデーション手法を詳しく解説します!
今回は数理最適化を例に挙げましたが、入力データのバリデーションの重要性はソフトウェアエンジニアリングに共通するテーマです。
【Udemy講座公開のお知らせ】
このたびUdemyで数理最適化の講座を公開しました!この講座は「数理最適化を勉強してみたいけど数式が多くて難しい…」という方向けに、どうやって最適化問題を定式化すれば良いかを優しく丁寧に解説しています!
こんなシチュエーションってよくあるよね(配送計画問題の例)
それではまず最初に配送計画問題を題材にして、あるあるのシチュエーションを3つほど紹介したいと思います。なお今回はいずれも入力データが2つのcsvで渡されたと仮定します。1つは各地点の座標と荷物量を表すファイルで、もう1つは各車両の容量を表すファイルです。
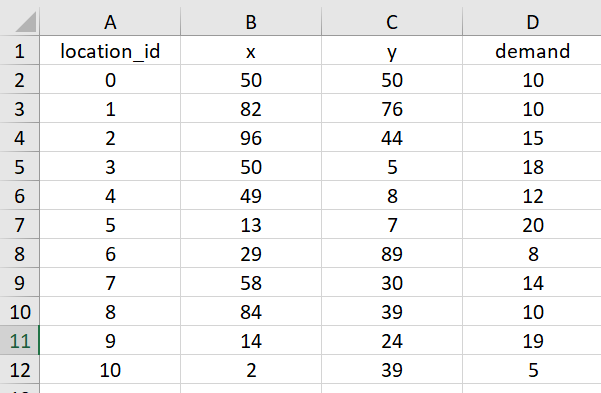
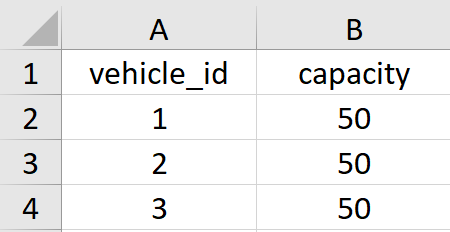
数値が欲しいのに文字列になっている
csvファイルを読み込んだ際、本来は120.5のような数値(floatやint)として扱いたい荷物量などが"120.5"や”120.5kg"といった文字列として読み込まれてしまうパターンです。
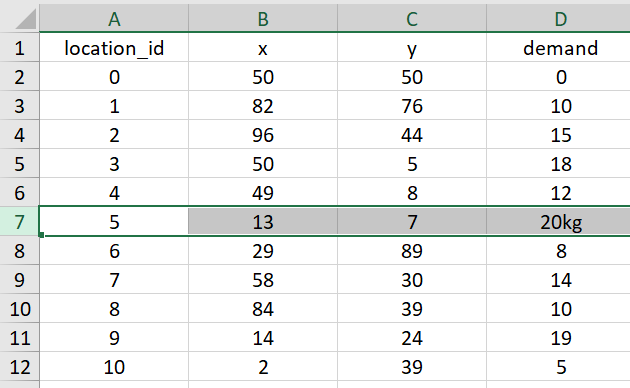
たとえば上図を見ると、demand列の7行目にだけ「kg」が付いています。このままPandasで読み込むと列全体が文字列(str型)として扱われてしまい、計算のどこかでエラーが出る原因になります
「これくらい見ればわかるだろ」と思うかもしれません。しかしこれが数万行のデータになったり、あるいはパッと見では気づけない全角の12.5等が混ざっていたりすると途端に見つけるのが大変になります。
それに一度こういうことが起きると計算を実行するたびに「どこかにミスがあるかも……」と疑わなければならず、精神的なストレスもバカになりません。毎回血眼になって目視でチェックを繰り返すのはエンジニアの本来の仕事ではないはずです。
0以上の数値であるはずがマイナスの数値になっている
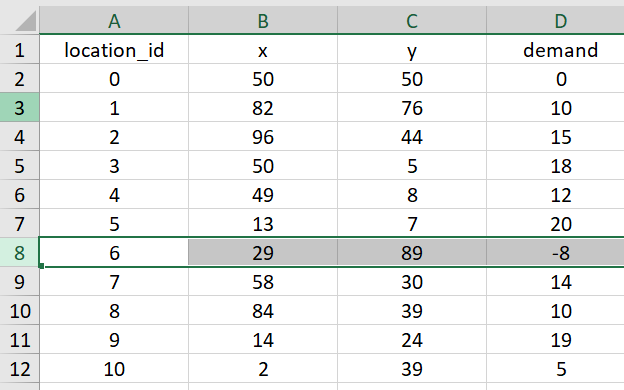
各地点に届ける荷物量は0以上の値を持っているはずです。それにもかかわらず上図を見ると8行目のdemand列が-8とマイナスの値を取っていますね。仮にこれに気づかず最適化を実行してしまうと、容量制限の制約でおかしなことになってしまいます。
例えば容量制限が50の車両の場合、本来容量制限に引っかかって1台で地点5,6,7,8に荷物を届けることはできません。
\(20+8+14+10=52 > 50\)
しかし入力ミスに気付かず地点6のに届ける荷物量を-8とした場合、1台で地点5,6,7,8に荷物を届けても容量制限を満たすことになってしまいます。
\(20-8+14+10=36 < 50\)
そうすると本来実行不能な解が許容解として得られてしまい、最悪の場合最適化を実行してから気づいてやり直しなんてことも考えられます。
数値の大小関係が間違っている
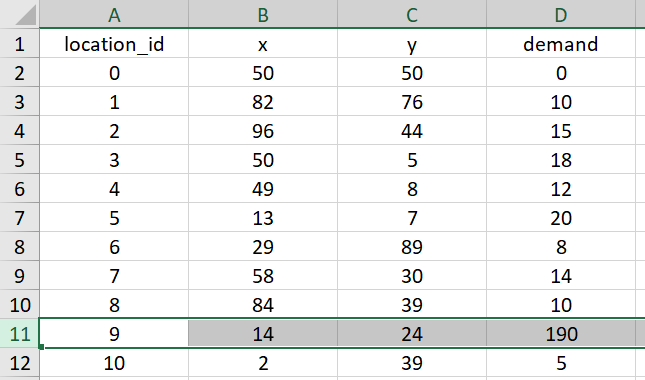
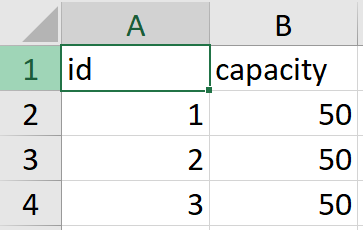
上図を見ると、地点9に届ける荷物量が190となっています。これだけ見ると別に何の問題もないですが、車両データを見てみると、どの車両も容量制限が50となっています。これでは明らかに地点9に荷物を届けることができずinfeasibleとなってしまいます。本当は19と入力するはずが、間違えて190と入力してしまったようです。
これはdemand列の最大値とcapacity列の最大値を比較すれば簡単に分かります。demand列の最大値の方が小さければ問題なく、大きければ異常があります。この判定も最適化を実行する前に、事前にバリデーションしておけば無駄な時間を過ごさなくて済みますね。
Pydanticってなに?
ということでここまで入力データのバリデーションがいかに重要かを話してきました。ではPythonでこれを実現するにはどうすればよいのでしょうか? そこで登場するのがPydanticです。
PydanticはPythonでバリデーションができる、最も有名なライブラリの1つです。Pydanticを使えば1つ前の章で話したような
- このデータは数値じゃないとダメ!
- このデータは0以上の値じゃないとダメ!
- このデータとあのデータは大小関係がある!
といったバリデーションを簡単に行うことができます。また単にエラーを見つけるだけでなく、文字列で届いた数字を自動で数値型に変換してくれる機能も備わっているなど、非常に重宝するライブラリです。
実際にPydanticを使ってみよう!
Pydanticの詳しい説明やコーディングの方法は公式docsに載っているのでそちらを確認してください。この記事では第2章で紹介した3つのバリデーションを行う方法を紹介したいと思います!それでは実際に配送計画問題を解くコードの中身とpydanticの使い方を詳しく見ていきましょう!
コードの全貌
まず最初にコードの全貌を載せます。今回はpydanticを使うことが目的なので最適化実行ファイルや後処理実行ファイルなどpydanticとは関係ない所はあまり説明しません。
ディレクトリ構成は下記のようにしました。これも本題ではありませんが、環境構築にはuvを使っています。
cvrp_pydantic/
├── .python-version
├── pyproject.toml
├── uv.lock
├── main.py ← エントリポイント
├── data/ ← 入力データが保管されるフォルダ
│ ├── locations.csv ← 地点の情報を持つcsvファイル
│ └── vehicles.csv ← 車両の情報を持つcsvファイル
└── src/
├── preprocess.py ← 前処理を行うファイル(ここでバリデーションを行う!)
├── postprocess.py ← 後処理を行うファイル
├── solver.py ← 最適化を行うファイル
└── schemas.py ← バリデーションの定義を行うファイルimport logging
from src.preprocess import load_and_validate_data
from src.postprocess import process_results
from src.solver import CVRPSolver
# ロギングの設定
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)
def main() -> None:
locations_file = "data/locations.csv"
vehicles_file = "data/vehicles.csv"
logger.info("データを読み込みます")
try:
input_data = load_and_validate_data(locations_file, vehicles_file)
logger.info("データの読み込みと検証が成功しました")
except Exception as e:
logger.error(f"データの検証エラー: {e}")
return
logger.info("最適化を実行します")
solver = CVRPSolver(input_data)
routes = solver.solve()
logger.info("結果を表示します")
process_results(routes, input_data)
if __name__ == "__main__":
main()
import logging
from src.schemas import CVRPInput
logger = logging.getLogger(__name__)
def process_results(routes: dict[int, list[int]], input_data: CVRPInput) -> None:
"""
VRP最適化の結果を計算して表示します。
"""
try:
total_dist = 0
node_map = {loc.location_id: loc for loc in input_data.locations}
for id, route in routes.items():
route_dist = 0
load = 0
# 表示用メトリクス計算
for k in range(len(route) - 1):
u, v = route[k], route[k+1]
# ユークリッド距離計算
d = ((node_map[u].x - node_map[v].x)**2 + (node_map[u].y - node_map[v].y)**2)**0.5
route_dist += d
load += node_map[v].demand
total_dist += route_dist
logger.info(f"車両 {id}: {route} | 距離: {route_dist:.2f} | 積載量: {load}")
logger.info(f"総距離: {total_dist:.2f}")
except:
logger.warning("後処理でエラーが発生しました")
import pandas as pd
import logging
from src.schemas import CVRPInput, Location, Vehicle
logger = logging.getLogger(__name__)
def load_and_validate_data(locations_path: str, vehicles_path: str) -> CVRPInput:
"""
位置情報と車両情報のCSVファイルを読み込み、Pydanticモデルにパースし、
バリデーション済みのCVRPInputオブジェクトを返す
"""
# CSV読み込み
df_loc = pd.read_csv(locations_path)
df_veh = pd.read_csv(vehicles_path)
# 位置データをバリデーションしてリストに格納
locations = []
for _, row in df_loc.iterrows():
locations.append(Location(
location_id=row['location_id'],
x=row['x'],
y=row['y'],
demand=row['demand']
))
# 車両データをバリデーションしてリストに格納
vehicles = []
for _, row in df_veh.iterrows():
vehicles.append(Vehicle(
vehicle_id=row['vehicle_id'],
capacity=row['capacity']
))
# CVRPInputオブジェクトを作成してバリデーションを行う
input_data = CVRPInput(locations=locations, vehicles=vehicles)
return input_data
from pydantic import BaseModel, Field, field_validator, model_validator
# 位置情報を表すクラス
class Location(BaseModel):
location_id: int
x: float
y: float
demand: float = Field(ge=0)
# 車両情報を表すクラス
class Vehicle(BaseModel):
vehicle_id: int
capacity: float = Field(gt=0)
# 配送計画問題の入力データを表すクラス
class CVRPInput(BaseModel):
locations: list[Location]
vehicles: list[Vehicle]
@field_validator('locations')
@classmethod
def validate_depot_exists(cls, v):
if not any(loc.location_id == 0 for loc in v):
raise ValueError("デポ(location_id = 0)の情報がlocations.csvに存在する必要があります。")
return v
@model_validator(mode='after')
def validate_capacity_feasibility(self):
# 最大荷物量と最大車両容量を計算して比較する。最大荷物量が最大車両容量を超える場合は実行不可能。
max_demand = max((loc.demand for loc in self.locations), default=0)
max_capacity = max((veh.capacity for veh in self.vehicles), default=0)
if max_demand > max_capacity:
raise ValueError(f"実行不可能: 最大需要 ({max_demand}) が最大車両容量 ({max_capacity}) を超えています。")
return self
import pulp
import logging
import itertools
from src.schemas import CVRPInput
logger = logging.getLogger(__name__)
# 容量制約付き配送計画問題を定式化して解く最適化モデル
class CVRPSolver:
def __init__(self, input_data: CVRPInput):
self.locations = input_data.locations
self.vehicles = input_data.vehicles
self.num_vehicles = len(self.vehicles)
self.prob = pulp.LpProblem("CVRP", pulp.LpMinimize)
# パラメータ設定
self.V = [loc.location_id for loc in self.locations]
self.V_0 = [i for i in self.V if i != 0]
self.R = [v.vehicle_id for v in self.vehicles]
self.q = {loc.location_id: loc.demand for loc in self.locations}
self.Q = {v.vehicle_id: v.capacity for v in self.vehicles}
self.dist = self._calculate_distance_matrix()
self._add_variables() # 変数の設定
self._add_objective() # 目的関数の設定
self._add_constraints() # 制約条件の設定
def _calculate_distance_matrix(self) -> dict[tuple[int, int], float]:
"""任意の2地点間のユークリッド距離を計算する"""
dist = {}
node_map = {loc.location_id: loc for loc in self.locations}
for i in self.V:
for j in self.V:
d = ((node_map[i].x - node_map[j].x)**2 + (node_map[i].y - node_map[j].y)**2)**0.5
dist[(i, j)] = d
return dist
def _powerset(self, locations: list[int]) -> list]:
"""地点集合の部分集合を生成する(部分巡回路除去制約で使用)"""
return list(
itertools.chain.from_iterable(itertools.combinations(locations, r)
for r in range(len(locations)+1))
)
def _add_variables(self):
# 変数: x[r, i, j] (車両rがiからjへ移動するか)
self.x = pulp.LpVariable.dicts(
"x",
[(r, i, j) for r in self.R for i in self.V for j in self.V if i != j],
cat="Binary"
)
def _add_objective(self):
# 目的関数: 総移動距離の最小化
self.prob += pulp.lpSum(
self.dist[i, j] * self.x[r, i, j]
for r in self.R for i in self.V for j in self.V if i != j
)
def _add_constraints(self):
# 1. 各顧客には必ず1回訪れる
for j in self.V_0:
self.prob += pulp.lpSum(self.x[r, i, j] for r in self.R for i in self.V if i != j) == 1
# 2. 各車両はデポを1回出発する
for r in self.R:
self.prob += pulp.lpSum(self.x[r, 0, j] for j in self.V_0) == 1
# 3. フロー保存制約 (入ったら出る)
for r in self.R:
for j in self.V:
self.prob += (
pulp.lpSum(self.x[r, i, j] for i in self.V if i != j) -
pulp.lpSum(self.x[r, j, k] for k in self.V if j != k) == 0
)
# 4. 容量制約
for r in self.R:
self.prob += pulp.lpSum(
self.q[j] * self.x[r, i, j] for i in self.V for j in self.V_0 if i != j
) <= self.Q[r]
# 5. 部分巡回路除去制約 (Powerset)
subsets = self._powerset(self.V_0)
for S in subsets:
if len(S) >= 2:
self.prob += pulp.lpSum(
self.x[r, i, j] for r in self.R for i in S for j in S if i != j
) <= len(S) - 1
def solve(self) -> dict[int, list[int]]:
status = self.prob.solve(pulp.PULP_CBC_CMD(msg=0))
if status == pulp.LpStatusOptimal:
return self._extract_routes()
raise ValueError("最適化結果が得られませんでした")
def _extract_routes(self) -> dict[int, list[int]]:
routes = {}
for r in self.R:
path = []
curr = 0
# デポから開始してルート構築
while True:
next_node = None
for j in self.V:
if curr != j:
if pulp.value(self.x[r, curr, j]) > 0.5:
next_node = j
break
if next_node is None:
break
path.append(next_node)
curr = next_node
if curr == 0:
break
if path:
routes[r] = [0] + path
else:
pass
return routes
処理の流れをザックリ説明します。まずdataフォルダにあるlocations.csvとvehicles.csvが入力データとなります。ルートにあるmain.pyを実行すると、これらのcsvを受け取り、srcフォルダのpreprocess.pyで前処理をします。(このときにpydanticで入力データのバリデーションを行います。)
その後バリデーションされた入力データをsrcフォルダのsolver.pyに渡し、最適化を実行します。最適化が実行出来たら最適解のデータをsrcフォルダのpostprocess.pyに渡します。そして最後postprocess.pyで後処理をして終了、って流れです。
なのでpydanticによる入力データのバリデーションに関係するファイルはpreprocess.pyとschemas.pyの2つだけなんですよね。そのためここからはこの2つを中心に解説したいと思います。
schemas.py(バリデーションの定義をする部分)
from pydantic import BaseModel, Field, field_validator, model_validator
# 位置情報を表すクラス
class Location(BaseModel):
location_id: int
x: float
y: float
demand: float = Field(ge=0)
# 車両情報を表すクラス
class Vehicle(BaseModel):
vehicle_id: int
capacity: float = Field(gt=0)
# 配送計画問題の入力データを表すクラス
class CVRPInput(BaseModel):
locations: list[Location]
vehicles: list[Vehicle]
@field_validator('locations')
@classmethod
def validate_depot_exists(cls, v):
if not any(loc.location_id == 0 for loc in v):
raise ValueError("デポ(location_id = 0)の情報がlocations.csvに存在する必要があります。")
return v
@model_validator(mode='after')
def validate_capacity_feasibility(self):
# 最大荷物量と最大車両容量を計算して比較する。最大荷物量が最大車両容量を超える場合は実行不可能。
max_demand = max((loc.demand for loc in self.locations), default=0)
max_capacity = max((veh.capacity for veh in self.vehicles), default=0)
if max_demand > max_capacity:
raise ValueError(f"実行不可能: 最大需要 ({max_demand}) が最大車両容量 ({max_capacity}) を超えています。")
return selfそれではまずpydanticを使ったバリデーションの定義を行います。
from pydantic import BaseModel, Field, field_validator, model_validatorまずこの部分でpydanticからBaseModel,Field,field_validator,model_validatorの4つをインポートします。これらの説明は後で詳しく行います。
# 位置情報を表すクラス
class Location(BaseModel):
location_id: int
x: float
y: float
demand: float = Field(ge=0)この部分で位置情報を表すクラスを定義しています。location.csvの各行データがこのクラスに変換されるイメージです。この際にpydanticのBaseModelを継承していることに注意してください。pydanticによるバリデーションを行う場合はBaseModelを継承させます。
そしてLocationクラスの属性にlocation_id,x,y,demandの4つを追加しています。ここで、location_id: intやx: floatのように各属性に型を設定していますね。これがバリデーションです。
location_id,x,y,demandのようにどんな型かを定義され、バリデーションの対象となる属性をのことをフィールドと呼びます。
例えばlocation_idはint型(整数)しか受け付けず、例えばstr型(文字列)が入力されると「intで入力してください!」というエラーを出します。

実際に文字列を入力してしまうと上のようにエラーが出てしまいます。(invalid literal...の部分が、pydanticによるエラー文です。)これによって最適化を実行する前に、あ、入力データにエラーがあるなってのがすぐに分かります。
pydanticはlocation_idに文字列の”1"を入力してもエラーを吐かずint型に直して処理を進めます。(”1"→1と変換)
もしこのような処理を防ぎたい場合はField(strict=True)を追加することでエラーを出すことができます。なお次で詳しく説明しますがFieldはフィールドに詳細な制約を追加することができる関数です。
class Location(BaseModel):
location_id: int = Field(strict=True)demandの所を見てみると、float型と定義した後Field(ge=0)というのが書かれていますね。Fieldはpydanticの関数で、フィールドに詳細な制約を追加することができる関数です。代表的な制約を下に書いておきます。
| 代表的な引数 | 引数の意味 |
|---|---|
ge/le | 不等号(≧ / ≦) |
gt/lt | 不等号(> / <) |
max_length/min_length | 文字列の長さの最大/最小値 |
default | デフォルト値 |
description | フィールドの説明 |
第2章で話したように、荷物量がマイナスになると最適化結果がおかしなことになるので、Field(ge=0)を追加してdemandの値が0以上じゃないとエラーが出るようにしています。
# 車両情報を表すクラス
class Vehicle(BaseModel):
vehicle_id: int
capacity: float = Field(gt=0)こちらは車両情報を表すクラスを定義しています。ここではvehicle_idとcapacityの2つをフィールドとして定義しています。capacityは車両の容量制限を表すので0より大きい値が入力されるはずですね。従ってField(gt=0)を書いています。
# 配送計画問題の入力データを表すクラス
class CVRPInput(BaseModel):
locations: list[Location]
vehicles: list[Vehicle]
@field_validator('locations')
@classmethod
def validate_depot_exists(cls, v):
if not any(loc.location_id == 0 for loc in v):
raise ValueError("デポ(location_id = 0)の情報がlocations.csvに存在する必要があります。")
return v
@model_validator(mode='after')
def validate_capacity_feasibility(self):
# 最大荷物量と最大車両容量を計算して比較する。最大荷物量が最大車両容量を超える場合は実行不可能。
max_demand = max((loc.demand for loc in self.locations), default=0)
max_capacity = max((veh.capacity for veh in self.vehicles), default=0)
if max_demand > max_capacity:
raise ValueError(f"実行不可能: 最大需要 ({max_demand}) が最大車両容量 ({max_capacity}) を超えています。")
return selfこの部分では配送計画問題の入力データを表すクラスを定義しています。フィールドはlocationsとVehiclesの2つで、それぞれ先ほど定義したlocationとVehicleを要素に持つリストです。例えば7地点のデータが入力されたときのlocationsは7個の要素を持つリストになり、各要素が各地点を表すlocationクラスのインスタンスとなります。
そしてこのCVRPInputクラスは2つのメソッドを持っていますね。1つがvalidate_depot_existsでもう1つがvalidate_capacity_feasibilityです。これらはより詳細なバリデーションを行う関数です。それぞれ何をやっているのかを詳しく見ていきます。
フィールドごとにバリデーションを行いたいとき
@field_validator('locations')
@classmethod
def validate_depot_exists(cls, v):
if not any(loc.location_id == 0 for loc in v):
raise ValueError("デポ(location_id = 0)の情報がlocations.csvに存在する必要があります。")
return vこのコードがやっていることは「デポ(location_idが0となるような位置情報)が存在するかをチェックする」です。デポが無いと意味わかんないですもんね。
上から順にみていきます。1番上の@field_validatorはフィールドごとにバリデーションを行うときに使います。型ヒントや、上下限値の設定などの簡単なバリデーションはこれまで説明したようにaaa: int = Field(ge=0)という感じで達成できますが、もっと複雑なバリデーションを行いたいときは@field_validatorを付けてバリデーションの中身をメソッドとして定義します。field_validatorの引数にはそのクラスの中でバリデーションを行いたいフィールド名を入力します。今回は位置情報なので@field_validator('locations')としています。
複数のフィールド間のバリデーションを行いたいとき
@model_validator(mode='after')
def validate_capacity_feasibility(self):
# 最大荷物量と最大車両容量を計算して比較する。最大荷物量が最大車両容量を超える場合は実行不可能。
max_demand = max((loc.demand for loc in self.locations), default=0)
max_capacity = max((veh.capacity for veh in self.vehicles), default=0)
if max_demand > max_capacity:
raise ValueError(f"実行不可能: 最大需要 ({max_demand}) が最大車両容量 ({max_capacity}) を超えています。")
return selfこのコードがやっていることは「荷物量の最大値が容量の最大値以下かどうかをチェックする」です。これを満たしていないと荷物を配達できない地点が生まれてしまいますもんね。
これをチェックするためには、locationクラスのdemandと、Vehicleクラスのcapacityという2つのフィールド間の関係をチェックする必要があり、field_validatorは使えません。このように複数のフィールド間のバリデーションを行いたいときはmodel_validatorを使います。
引数にmode='after'とありますが、これは全てのバリデーションが終わってインスタンス化されたオブジェクトに対してバリデーションを行うことを表します。一方でmode='before'とすると入力データを受け取った直後の状態でバリデーションを行うことを表します。
preprocess.py(実際にバリデーションを行う部分)
import pandas as pd
import logging
from src.schemas import CVRPInput, Location, Vehicle
logger = logging.getLogger(__name__)
def load_and_validate_data(locations_path: str, vehicles_path: str) -> CVRPInput:
"""
位置情報と車両情報のCSVファイルを読み込み、Pydanticモデルにパースし、
バリデーション済みのCVRPInputオブジェクトを返す
"""
# CSV読み込み
df_loc = pd.read_csv(locations_path)
df_veh = pd.read_csv(vehicles_path)
# 位置データをバリデーションしてリストに格納
locations = []
for _, row in df_loc.iterrows():
locations.append(Location(
location_id=row['location_id'],
x=row['x'],
y=row['y'],
demand=row['demand']
))
# 車両データをバリデーションしてリストに格納
vehicles = []
for _, row in df_veh.iterrows():
vehicles.append(Vehicle(
vehicle_id=row['vehicle_id'],
capacity=row['capacity']
))
# CVRPInputオブジェクトを作成してバリデーションを行う
input_data = CVRPInput(locations=locations, vehicles=vehicles)
return input_data
次に入力データのバリデーションを行う前処理部分をpreprocess.pyに実装します。実行自体は非常に簡単で、通常のクラスと同様に各引数にデータを渡してインスタンス化するだけです。このインスタンス生成の過程で、定義したバリデーション処理が自動的に実行されます。
# 位置データをバリデーションしてリストに格納
locations = []
for _, row in df_loc.iterrows():
locations.append(Location(
location_id=row['location_id'],
x=row['x'],
y=row['y'],
demand=row['demand']
))この部分でまず位置データのバリデーションを行っています。まずlocationsを空リストとして定義して、冒頭で読み込んだdf_locの各行を1つずつ取ってきて、Locationクラスに突っ込んでいます。この段階でバリデーションが実行され、特に問題が無ければインスタンス化され、locationsリストに追加されます。
# 車両データをバリデーションしてリストに格納
vehicles = []
for _, row in df_veh.iterrows():
vehicles.append(Vehicle(
vehicle_id=row['vehicle_id'],
capacity=row['capacity']
))この部分では車両データのバリデーションを行っています。流れはlocationsの処理と全く同じです。バリデーション時にエラーが無かったらvehiclesリストにVehicleクラスのインスタンスが追加されます。
# CVRPInputオブジェクトを作成してバリデーションを行う
input_data = CVRPInput(locations=locations, vehicles=vehicles)最後にこの部分でCVRPInputクラスのインスタンスを作成しています。これも通常のクラスと同じように引数に先ほど作ったlocationsとvehiclesを入力して、バリデーションに問題が無かったらCVRPInputクラスのインスタンスを作成します。
実際に動かしてみる
それでは最後に、実際に動かしてみましょう。入力データに問題がない場合と、問題がある場合それぞれの実行結果を見ていきます。
入力データに問題がない場合

こんな感じでちゃんとデータの読み込みと検証が成功して最適化を実行することができました。
数値を想定しているのに文字列が入力されている場合
上図のように各地点に届ける荷物量が文字列になる場合でプログラムを実行してみましょう。

ちゃんとエラーが出ていますね。エラーの文章を見ると、floatを想定しているのに'20kg'っていうstrが入力されているよ!と教えてくれています。
0以上の数値を想定しているのにマイナスの数値が入力されている場合
それでは次に0以上の数値を想定しているのにマイナスの数値が入力されている場合も見ていきましょう。

こちらもちゃんとエラーが出ていますね。エラー文を見ると0以上の値を想定しているのに-8が入力されているよ!と教えてくれています。
荷物量が容量を上回っている場合
それでは最後に荷物量が車両の容量を上回っている場合について見ていきましょう。

こちらもちゃんとエラーが出ていますね。エラー文を見てみると最大需要(190.0)が最大車両容量(50.0)を超えています。と教えてくれています。(こちらはvalidate_capacity_feasibilityメソッド内で自分で定義したエラー文です。)
おわりに
今回は数理最適化を実行する前にpydanticで入力データのバリデーションをした方が良いという話をしました!
今後もこのような数理最適化に関する記事を書いていきます!
最後までこの記事を読んでくれてありがとうございました。
普段は組合せ最適化の記事を書いてたりします。
ぜひ他の記事も読んでみてください!
このブログの簡単な紹介はこちらに書いてあります。
興味があったら見てみてください。
このブログでは経営工学を勉強している現役理系大学生が、経営工学に関することを色々話していきます!
ぼくが経営工学を勉強している中で感じたことや、興味深かったことを皆さんと共有出来たら良いなと思っています。
そもそも経営工学とは何なのでしょうか。Wikipediaによると
経営工学(けいえいこうがく、英: engineering management)は、人・材料・装置・情報・エネルギーを総合したシステムの設計・改善・確立に関する活動である。そのシステムから得られる結果を明示し、予測し、評価するために、工学的な分析・設計の原理・方法とともに、数学、物理および社会科学の専門知識と経験を利用する。
引用元 : 経営工学 – Wikipedia
長々と書いてありますが、要は経営、経済の課題を理系的な観点から解決する学問です。

