


- 短時間でまあまあ良い解が欲しいな…
- 貪欲法ってなに?
- 貪欲法でどれくらいの精度の解が得られるの?
こんにちは!しゅんです!
最近ある問題をソルバーで解いてたときにこう思いました。
別に最適解を求める必要はないから、短時間である程度良い解を求めたいな~
特に実務で最適化問題を扱うときはこう考える場合が多いんじゃないでしょうか。ということでこの記事では、貪欲法で問題を解いたときに最適解と比べてどれくらいギャップがあるのかを調査してみました!
それではやっていきましょう!
普段は組合せ最適化の記事を書いてたりします。
ぜひ他の記事も読んでみてください!
このブログの簡単な紹介はこちらに書いてあります。
興味があったら見てみてください。
このブログでは経営工学を勉強している現役理系大学生が、経営工学に関することを色々話していきます!
ぼくが経営工学を勉強している中で感じたことや、興味深かったことを皆さんと共有出来たら良いなと思っています。
そもそも経営工学とは何なのでしょうか。Wikipediaによると
経営工学(けいえいこうがく、英: engineering management)は、人・材料・装置・情報・エネルギーを総合したシステムの設計・改善・確立に関する活動である。そのシステムから得られる結果を明示し、予測し、評価するために、工学的な分析・設計の原理・方法とともに、数学、物理および社会科学の専門知識と経験を利用する。
引用元 : 経営工学 – Wikipedia
長々と書いてありますが、要は経営、経済の課題を理系的な観点から解決する学問です。
集合被覆問題ってなに?
まず最初に集合被覆問題がどんな問題化について説明します。集合 \(U=\{e_1,e_2,…,e_n\}\) と \(U\) の部分集合族 \(\mathcal S = \{S_1,S_2,…,S_m\}\) について考えます。また各集合 \(S_k\) にはコスト \(c_{S_{k}}\) が与えられています。
例)
\(U = \{1,2,3,4,5,6\}\)
\(\mathcal S = \{S_1,S_2,S_3,S_4\}\)
\(S_1=\{1,2,3\}, \; c_{S_{1}}=3\)
\(S_2=\{3,5\}, \; c_{S_{2}}=1\)
\(S_3=\{4,5,6\}, \; c_{S_{3}}=2\)
\(S_4=\{4,6\}, \; c_{S_{4}}=2\)
今いくつかの集合を取ってきて、\(U\)の全ての要素をカバー(被覆)することを考えます。
例)
\(\{S_1,S_3\}\)はOK(\(S_1 \cup S_3 = \{1,2,3,4,5,6\}\))
\(\{S_1,S_2\}\)はNG(\(S_1 \cup S_2 = \{1,2,3,5\}\))
\(\{S_1,S_2,S_4\}\)はOK(\(S_1 \cup S_2 \cup S_4 = \{1,2,3,4,5,6\}\))
この中でコストの合計が最小になるようなものを見つけるのが集合被覆問題です。
例)
\(\{S_1,S_3\}\)のコスト:\(c_{S_{1}}+c_{S_{3}}=3+2=5\)
\(\{S_1,S_2,S_4\}\)のコスト:\(c_{S_{1}}+c_{S_{2}}+c_{S_{4}}=3+1+2=6\)
この問題例だと最適解は\(\{S_1,S_3\}\)となります。
貪欲法ってなに?
それでは次に貪欲法(Greedy Algorithm)について簡単に説明します。貪欲法を一言で説明すると
そのときどきで最も「よさそう」な選択肢を取っていくことで解を構築する手法
です。最適解を必ず得られるわけではないですが、ある程度精度が高い解を比較的シンプルで高速に実行できることが多いのが魅力です。
貪欲法は問題ごとに設定します。もちろん集合被覆問題向けの貪欲法も存在します。今回はこの集合被覆問題を解くための貪欲法を使って、どれくらいの精度の解が得られるのかを調査したいと思います。
集合被覆問題を貪欲法で解く方法は?
それでは次に今回の本題である、
集合被覆問題を貪欲法で解く方法
を解説したいと思います。もう一度貪欲法がどんなアルゴリズムかを説明すると
そのときどきで最も「よさそう」な選択肢を取っていくことで解を構築する手法
です。このことを頭に入れてここからの話を読むと理解しやすいと思います。
最も「よさそう」な選択肢ってなんだろう?
それではまず最初に最も「よさそう」な選択肢ってなんだろう?ということを考えたいと思います。直観的に考えると
「コストが少なく、かつ被覆できる要素数が多い集合を選ぶ」
のが最もよさそうな選択肢のように思えます。具体例を使って説明します。
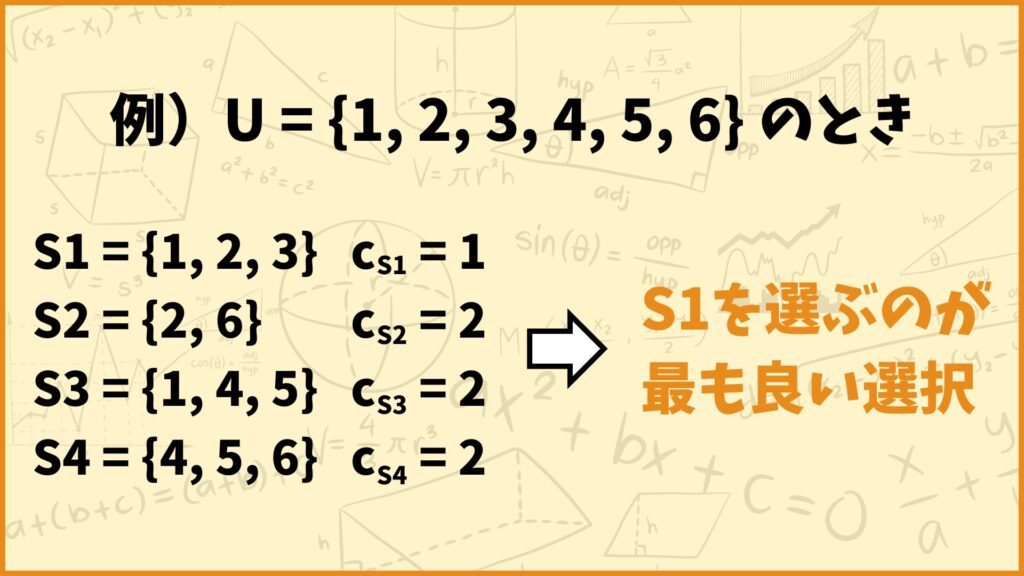
例えば上図の問題例において、どの集合を選ぶのが一番良い選択なのかを考えます。仮に \(S_1\) を選ぶとコスト1で3つの要素 \(1,2,3\) をカバーすることができます。
一方で \(S_2\) を選ぶとコスト2で2つの要素 \(2,6\) しかカバーすることができません。そう考えたときに最も良い選択、いわばもっともコスパが良い選択は
\(\frac{\text{被覆できる要素数}}{\text{コスト}}\)
が最大のものを選ぶことだと考えられます。上の例で言うと
\(S_1 : \frac{3}{1}=3\)
\(S_2 : \frac{2}{2}=1\)
\(S_3 : \frac{3}{2}=1.5\)
\(S_4 : \frac{3}{2}=1.5\)
と計算でき、\(S_1\) を選ぶのが最も良い選択となります。

それでは \(S_1\) を選んだ次はどの集合を選べばよいかを考えましょう。基本的にはさっきと同じように考えれば良いのですが、既に \(1,2,3\)は被覆されていることに注意します。
例えば \(S_2\) は2つの要素を被覆できますが、既に要素 \(2\) は被覆されているので\(\frac{\text{被覆できる要素数}}{\text{コスト}}\)の値は \(\frac{1}{2}\)となります。そのため厳密に言うと
\(\frac{\text{まだ被覆されていない要素の中で被覆できる要素数}}{\text{コスト}}\)
が最大になるような集合を選ぶのが最も良い選択と考えます。これ以降、上の式を密度(density)と呼びます。
他の集合も同じように考えると
\(S_2 : \frac{1}{2}=0.5\)
\(S_3 : \frac{2}{2}=1\)
\(S_4 : \frac{3}{2}=1.5\)
となり、\(S_4\) を選ぶのが最も良さそうな選択となります。
この時点で全ての集合を被覆できたので、最終的に出力する解は\(\{S_1,S_4\}\)でコストの合計は3となります。ちなみにこの解は最適解となります。
数式を使って貪欲法を説明する
それでは次に、今説明した貪欲法を数式で表してみましょう。
貪欲法に用いる文字の定義:
\(U=\{e_1,e_2,…,e_n\}\) : 被覆したい集合
\(\mathcal{S} = \{S_1,S_2,…,S_m\}\):\(U\) の部分集合族
\(c_S\):集合 \(S \in \mathcal{S}\) のコスト
\(\mathcal{C}\subseteq \mathcal{S}\):アルゴリズム中で保持される \(\mathcal{S}\) の部分族
\(T\):\(\mathcal{C}\) が被覆する \(U\) の要素の集合
\(\text{density}(S) = \frac{c_S}{|S\backslash T|}\):集合 \(S\) の密度
貪欲法の手順:
STEP 1:\(T \leftarrow \emptyset, \mathcal{C} \leftarrow \emptyset\) とする。
STEP 2:\(T \ne U\) である間は以下の2-1~2-2を繰り返す。
2-1:\(S\backslash \mathcal{C}\) の要素の中で\(\text{density}(S)\) が最小である集合 \(S\) を選ぶ。
2-2:\(T \leftarrow T \cup S, \mathcal{C} \leftarrow \mathcal{C} \cup \{S\}\) と更新する。
STEP 3:\(T=U\) となったら \(\mathcal{C}\) を出力する。
数式が入ってややこしくなりましたが、やってることはさっきと一緒です。さっきの例を使って詳しく見ていきます。
STEP 1では\(T = \emptyset, \mathcal{C} = \emptyset\)とします。
1回目の反復の2-1では
\(\text{density}(S_1)=\frac{c_{S_1}}{|\{1,2,3\}|}=3\)
\(\text{density}(S_2)=\frac{c_{S_2}}{|\{2,6\}|}=1\)
\(\text{density}(S_3)=\frac{c_{S_3}}{|\{1,4,5\}|}=1.5\)
\(\text{density}(S_4)=\frac{c_{S_4}}{|\{4,5,6\}|}=1.5\)
となるので \(S_1\) を選びます。
2-2では \(T = \{1,2,3\}, \mathcal{C}=\{S_1\}\) とします。
2回目の反復の2-1では
\(\text{density}(S_2)=\frac{c_{S_2}}{|\{6\}|}=0.5\)
\(\text{density}(S_3)=\frac{c_{S_3}}{|\{4,5\}|}=1\)
\(\text{density}(S_4)=\frac{c_{S_4}}{|\{4,5,6\}|}=1.5\)
となるので \(S_4\) を選びます。
2-2では \(T = \{1,2,3,4,5,6\}, \mathcal{C}=\{S_1,S_4\}\) とします。この時点で \(T=U\) となったので \(\mathcal{C}= \{S_1,S_4\}\) を出力します。
貪欲法が最適解を出力するとは限らない
さっきまで考えていた例では貪欲法が最適解を出力していましたが、どんな問題例でも最適解を出力するとは限らないです。
例えば下記の問題例を考えます。
\(U = \{1,2,3,4\}\)
\(\mathcal{S} = \{S_1,S_2,S_3,S_4\}\)
\(S_1 = \{1,2\}, c_{S_{1}}=1\)
\(S_2 = \{2,3,4\}, c_{S_{2}}=1\)
\(S_3=\{1,3\}, c_{S_{3}}=1\)
\(S_4=\{4\}, c_{S_{4}}=0.1\)
この問題の最適解は \(\{S_1,S_2\}\) でコストの合計は2です。しかし貪欲法を使用すると
\(\text{density}(S_1)=\frac{2}{1}=2\)
\(\text{density}(S_2)=\frac{3}{1}=3\)
\(\text{density}(S_3)=\frac{2}{1}=2\)
\(\text{density}(S_4)=\frac{1}{0.1}=10\)
となり、\(S_4\)を選んでしまいます。その後も貪欲法を続けると最終的に得られる解は \(\{S_1,S_2,S_4\}\) となり、コストの合計は2.1となります。これは最適解ではありません。
ちなみにこの貪欲法は集合被覆問題に対する\(O(\log{n})\)近似解を求めることが証明されています。もう少し詳しく言うと集合被覆問題の最適値を\(\text{OPT}\)、貪欲法が返す解の目的関数値を\(\text{OPT}^{A}\)とすると、頂点数を \(n\) としたとき
\(\text{OPT}^A \leq (1+\frac{1}{2}+\cdots +\frac{1}{n})\text{OPT} = H_n \cdot \text{OPT}\)
であることが証明されています。ちなみに \(H_n = (1+\frac{1}{2}+\cdots +\frac{1}{n})\) は \(n\) 番目の調和級数で、\(y=\log{x}\) の積分近似を考えれば \(H_n = O(log{n})\) であることが分かります。
ここの詳しい証明は下記のテキストが非常にわかりやすかったです。

pythonで実験してみた
それでは最後に、貪欲法で得られた解が最適解と比べてどれくらいの精度なのかを実験してみたいと思います。実験方法は下記の通りです。
各実験で100回集合被覆問題を解き、CBCソルバーで裁定買いを求めた場合と貪欲法を使用した場合を比較する
実験1:
\(|U|=20,|\mathcal{S}|=30\)の問題サイズで下記の値を計算する。
・(最適値 = 貪欲法の目的関数値)となった回数
・(貪欲法の目的関数値)/(最適値)の値
・貪欲法にかかった時間の平均値
・最適解を求めるためにかかった時間の平均値(整数計画問題をソルバーで解く)
実験2:
\(|U|=200,|\mathcal{S}|=300\)の問題サイズで下記の値を計算する。
・(最適値 = 貪欲法の目的関数値)となった回数
・(貪欲法の目的関数値)/(最適値)の値
・貪欲法にかかった時間の平均値
・最適解を求めるためにかかった時間の平均値(整数計画問題をソルバーで解く)
貪欲法を実行するコード
import random
import pulp
import time
def generate_instance(n_elements, m_subsets, prob=0.3):
# ランダムに集合被覆問題のインスタンスを生成する関数
# U: 被覆すべき要素の集合(0,1,...,n_elements-1)
# S: Uの部分集合のリスト(各部分集合はランダムに選ばれる)
# costs: 各部分集合のコスト(ここでは1~10の整数)
U = set(range(n_elements))
S = []
costs = []
for i in range(m_subsets):
subset = {e for e in range(n_elements) if random.random() < prob}
if not subset:
subset.add(random.randint(0, n_elements - 1))
S.append(subset)
costs.append(random.randint(1, 10))
return U, S, costs
def greedy_set_cover(U, S, costs):
# 貪欲法による集合被覆問題の解法
# T: 現在カバーされている要素の集合
# cover_indices: 選ばれた部分集合のインデックスのリスト
start_time = time.time()
T = set()
cover_indices = []
remaining_indices = set(range(len(S)))
while T != U:
best_index = None
best_density = float('inf')
for i in remaining_indices:
new_elements = S[i] - T
if new_elements:
density = costs[i] / len(new_elements)
if density < best_density:
best_density = density
best_index = i
if best_index is None:
# もし新たにカバーする要素がない場合(通常は起こらない)break
break
cover_indices.append(best_index)
T.update(S[best_index])
remaining_indices.remove(best_index)
total_cost = sum(costs[i] for i in cover_indices)
end_time = time.time()
elapsed_time = end_time - start_time
return cover_indices, total_cost, elapsed_time
def solve_set_cover_ilp(U, S, costs):
# 整数計画問題による最適解を求める関数
# x_i: 部分集合 S[i] を採用するか否かのバイナリ変数
# 目的関数: Σ cost[i] * x_i を最小化
# 制約: 各要素 e ∈ U について、e を含む S[i] の x_i の和が1以上
prob = pulp.LpProblem("SetCover", pulp.LpMinimize)
x = [pulp.LpVariable(f"x_{i}", cat="Binary") for i in range(len(S))]
prob += pulp.lpSum(costs[i] * x[i] for i in range(len(S)))
for e in U:
prob += pulp.lpSum(x[i] for i in range(len(S)) if e in S[i]) >= 1, f"cover_{e}"
start_time = time.time()
prob.solve(pulp.PULP_CBC_CMD(msg=0))
end_time = time.time()
chosen_indices = [i for i in range(len(S)) if pulp.value(x[i]) > 0.5]
total_cost = pulp.value(prob.objective)
elapsed_time = end_time - start_time
return chosen_indices, total_cost, elapsed_time
def run_experiments(n_trials=100, n_elements=20, m_subsets=30, prob=0.3):
# 100回の実験を行い、貪欲法と整数計画問題による解の目的関数値のギャップを比較する関数
greedy_costs = []
greedy_time = []
optimal_costs = []
optimal_time = []
for _ in range(n_trials):
U, S, costs = generate_instance(n_elements, m_subsets, prob)
_, g_cost, g_elapsed_time = greedy_set_cover(U, S, costs)
_, o_cost, o_elapsed_time = solve_set_cover_ilp(U, S, costs)
greedy_costs.append(g_cost)
greedy_time.append(g_elapsed_time)
optimal_costs.append(o_cost)
optimal_time.append(o_elapsed_time)
gaps = [g / o for g, o in zip(greedy_costs, optimal_costs) if o > 0]
num_equal = sum(gap for gap in gaps if gap == 1)
avg_gap = sum(gaps) / len(gaps) if gaps else 0
g_avg_time = sum(greedy_time) / len(greedy_time)
o_avg_time = sum(optimal_time) / len(optimal_time)
print(f"(最適値 = 貪欲法の目的関数値)となる回数:{int(num_equal)}回 / {n_trials}回")
print(f"ギャップの平均値:{avg_gap}")
print(f"計算時間(貪欲法):{g_avg_time}")
print(f"計算時間(CBCソルバー):{o_avg_time}")
#return greedy_costs, optimal_costs # 具体的に最適解と貪欲法が返す解を見たければ「#」を消す実験1の結果

実験1の結果は上図のようになりました。これを見ると
貪欲法で最適解が得られた回数:27回
最適解が得られなかった回数:73回
となりました。70%くらいは最適解は得られていないということですね。ギャップの所を見ると平均して貪欲法で得られた解の目的関数値は最適値の約1.13倍であることが分かります。
\(n = 20\) なので、理論上最適値の約3.6倍の解が出力される可能性がありますが、全然ギャップが小さいです。
\(H_{20} = 1+\frac{1}{2}+\cdots + \frac{1}{20}=3.597739657143682…\)
となります。
計算時間を見ると
貪欲法:\(3.1 \times 10^{-4}\)秒
ソルバー:\(1.0 \times 10^{-1}\)秒
ということで貪欲法の方が約3000倍早く解が得られました。こんなに高速に解が得られるのに最適解とのギャップも1.13倍となるとかなり強力なアルゴリズムですね。(しかも必ず許容解が得られる。)
実験2の結果

実験2の結果は上図のようになりました。これを見ると
貪欲法で最適解が得られた回数:25回
最適解が得られなかった回数:75回
となりました。75%くらいは最適解は得られていないということですね。ギャップの所を見ると平均して貪欲法で得られた解の目的関数値は最適値の約1.11倍であることが分かります。
\(n = 200\) なので、理論上最適値の約5.88倍の解が出力される可能性がありますが、全然ギャップが小さいです。
\(H_{200 }= 1+\frac{1}{2}+\cdots + \frac{1}{200}=5.878030948121446\)
となります。
計算時間を見ると
貪欲法:\(1.4 \times 10^{-2}\)秒
ソルバー:\(4.7 \times 10^{0}\)秒
ということで貪欲法の方が約328倍早く解が得られました。問題のサイズが多くなっても、変わらずかなり高精度の解を短時間で出力してくれました。貪欲法は非常に強力な手法だと感じました。
おわりに
今回は集合被覆問題を貪欲法で解いてみました!
今後もこのような組合せ最適化に関する記事を書いていきます!
最後までこの記事を読んでくれてありがとうございました。

