


- 多項式回帰ってなに?
- pyhonで多項式回帰を実装する方法は?
- 過学習ってなに?
こんにちは!しゅんです!
今回は多項式回帰について解説していきたいと思います。
多項式回帰は回帰分析の中でも予測モデルが多項式になる分析です。ぼくがデータ分析の勉強をしていたときにでてきたので皆さんにもシェアしたいと思います!また今回は説明と一緒にpythonを使ってどんなものか確かめたいと思います。
それでは解説していきましょう!
普段は組合せ最適化の記事を書いてたりします。
ぜひ他の記事も読んでみてください!
このブログの簡単な紹介はこちらに書いてあります。
興味があったら見てみてください。
このブログでは経営工学を勉強している現役理系大学生が、経営工学に関することを色々話していきます!
ぼくが経営工学を勉強している中で感じたことや、興味深かったことを皆さんと共有出来たら良いなと思っています。
そもそも経営工学とは何なのでしょうか。Wikipediaによると
経営工学(けいえいこうがく、英: engineering management)は、人・材料・装置・情報・エネルギーを総合したシステムの設計・改善・確立に関する活動である。そのシステムから得られる結果を明示し、予測し、評価するために、工学的な分析・設計の原理・方法とともに、数学、物理および社会科学の専門知識と経験を利用する。
引用元 : 経営工学 – Wikipedia
長々と書いてありますが、要は経営、経済の課題を理系的な観点から解決する学問です。
多項式回帰ってなに?
ザックリ説明すると多項式回帰は直線じゃないデータを予測することです。下の例を見てみましょう。

上の表はあるアイスクリーム屋の1年間の売上データです。これを横軸が月、縦軸が売上のグラフで表したのが下の図です。
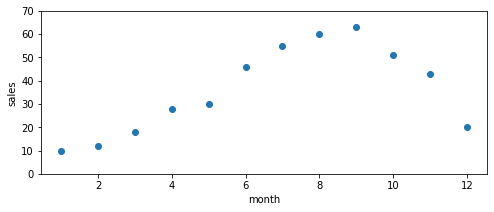
今回はこのデータを回帰で予測したいと思います。しかしここで1つ問題がでてきます。これ直線では予測できなさそうですよね。
直線で予測できそうな場合は線形回帰が使えるんですけど、今回の場合はそう簡単にはいかなさそうです。
こちらの記事で線形回帰について説明しています!

こんなときに使える手法の中の1つが多項式回帰です。例えば今回の例で言うと下の図のような曲線で回帰ができそうですよね。

ということで今回はこの多項式回帰をpythonでやる方法を説明したいと思います!
次の章ではもう少し具体的な説明をしたいと思います。高校数学の知識が必要なので難しいと感じるかもしれませんが、本格的にデータ分析を勉強するには数学の知識が必須なので知っておきたいです。
線形回帰じゃない回帰のことを一般に非線形回帰と呼びます。したがって今回説明する多項式回帰は非線形回帰の一種だと言えます。その他にも指数関数や対数関数など非線形回帰で使う関数モデルはたくさんあります。
線形(単)回帰と多項式回帰の数学的な違い
線形(単)回帰
線形(単)回帰は中学生で習う一次関数を使って予測をします。一次関数とは以下で表される関数です。
\(y = ax + b \;\; (a, b\text{は定数})\)
このモデルでは予測に使うデータ\(x\)を入力して、予測値\(y\)を手に入れます。さっきの例で言うと\(x\)が月データで\(y\)が売上に対応します。
線形(単)回帰では最小二乗法という手法を使って最適な\(a,b\)を求めます。最適な\(a,b\)のもとでは、実測値と予測値の差の合計が最小となります。
この一次関数をグラフで表すと直線になりますよね。だから線形回帰は直線で予測する回帰なんです。
より詳しく説明すると線形回帰が直線になるのは2次元のときの話です。3次元では平面となり、4次元以降は図で表すのが難しくなります。ただ今回はxとyしか使わない2次元平面の話なので線形=直線だと考えて大丈夫です。また2次元での線形回帰のことを特別に線形単回帰と呼んだりします。この後説明する線形回帰は全て線形単回帰だと思ってください。
このあと特徴量という言葉が登場しますがこれは\(x\)のことを指しています。
多項式回帰
多項式回帰では以下のような式を使って予測をします。
\(y = a_0 + a_1x + a_2x^2 + a_3x^3 + ・・・ + a_nx^n\)
\((a_0,…,a_n\text{は定数})\)
多項式回帰の場合は\(x\)の次数が増えます。例えば3次の多項式回帰だったら\(x^3\)まで、10次の多項式回帰だったら\(x^{10}\)まで使って予測をします。
線形回帰のときと一緒で、\(x\)にデータを入力すると予測値\(y\)が返ってきて、この予測値と実測値の差の合計が最も小さくなるような\(a_0,…,a_n\)を見つけるのが多項式回帰がやっていることです。
\(x\)の次数を増やすことでモデルがより柔軟になり、データの複雑なパターンを表現できるようになります。例えば高校で習う二次関数や三次関数は曲線ですよね。さらに4、5と次数を増やすほどくねくねしていました。このように\(x\)の次数を増やすことによって予測性能を上げることができるんです。
では次数を増やせば増やすほどモデルの予測精度は高くなるのでしょうか。それを確かめるために実際に多項式回帰をpythonでやってみましょう!
多項式回帰をpythonでやってみる
手順は以下の通りです。
今回はnumpyとmatplotlibを使います。
多項式回帰には必要のないステップですが視覚的にわかりやすいのでグラフを作成します。
PolynomialFeaturesを使います。次数は自分で設定できますが、今回は3次でやってみたいと思います。
多項式回帰を実行します。
ちゃんと予測できているかをグラフで確かめます。
1つずつ解説していきます。
STEP.1 事前準備、データの作成
# numpyをnpとしてインポート
import numpy as np
# matplotlibをpltとしてインポート
import matplotlib.pyplot as plt
# scikit-learnからPolynomialFeaturesをインポート
from sklearn.preprocessing import PolynomialFeatures
# scikit-learnからLinearRegressionをインポート
from sklearn.linear_model import LinearRegression
まず最初にnumpy, maptlotlib, scikit-learnからPolynomialFeaturesとLinearRegressionをインポートします。
numpyはデータを作成するために使います。
matplotlibはグラフを作成するために使います。
PolynomialFeaturesは多項式特徴量を生成するために使います。
LinearRegressionは線形回帰分析を行うために使います。
次にデータを作成します。月データをX、売上データをyとします。
# 月データを作成
X = np.arange(1,13)
# 売上データを作成
y = np.array([10,12,18,28,30,46,55,60,63,51,43,20])np.arange(1,13)で[1,2,3,4,5,6,7,8,9,10,11,12]というデータを作ることができます。
STEP.2 グラフを作成
多項式回帰に直接関係するわけではないですが、視覚的にわかりやすいのでデータの散布図を作成します。本題ではないのでコードの説明は飛ばします。
# グラフを作成
plt.figure(figsize=(8,3))
plt.scatter(X, y)
#yの上限、下限を設定
plt.ylim([0,70])
#x軸のラベルを設定
plt.xlabel("month")
#y軸のラベルを設定
plt.ylabel("sales")
#グラフを表示
plt.show()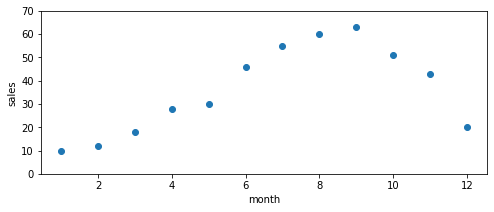
STEP.3 3次までの特徴量を生成
今回は3次の多項式を使って回帰を行いたいと思います。べき乗をpythonで扱うためにPolynomialFeaturesを使います。
それでは実際に3次までの特徴量を生成しましょう。
# 1, x, x^2, x^3 という4つの特徴量を作成するための前処理
X = X.reshape(-1,1)
polynomial_features = PolynomialFeatures(degree=3) #degreeで次数を設定
# 各列が 1, x, x^2, x^3 となる4列のデータが生成される
X_poly = polynomial_features.fit_transform(X)
「.reshape(-1,1)」によってXを変形しています。これによりデータを多項式回帰に使える形にします。(yには特に何もしなくて大丈夫です。)

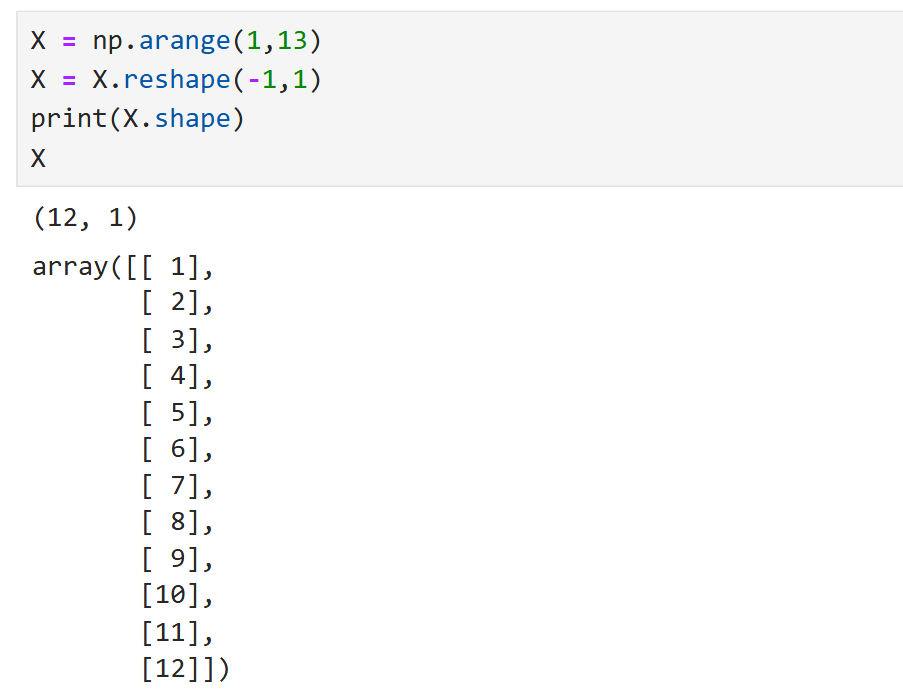
「X.reshape(-1,1)」によってXを1次元配列から2次元配列に変換しています。
次にPolynomialFeaturesを使って\(1, x, x^2, x^3\)までの特徴量を作ります。degreeの数字を変更することによって何次まで生成するかを決めることができます。今回は3次まで生成したいので「degree=3」にします。
最後に3次までの特徴量にX_polyと名前を付けます。。X_polyの中身は下のようになっています。
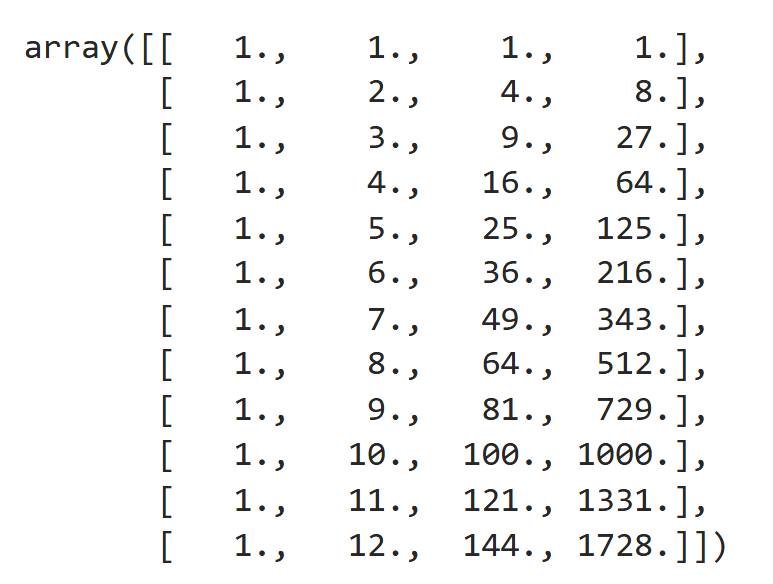
1月から12月までの月データを表示しています。このようにX_polyには1列目に1, 2列目にx, 3列目にx^2, 4列目にx^3の特徴量が格納されています。これを説明変数として使いたいと思います。
STEP.4 多項式回帰の実行
それでは実際に多項式回帰を実施しましょう。scikit-learnのLinearRegressionを使って多項式回帰を行います。
LinearRegressionは線形回帰をするためのものですが、実は多項式回帰はLinearRegressionを使ってできてしまいます。
多項式回帰なのにLinearRegressionを使うとなると、一見矛盾しているように聞こえますよね!解説していきます。
・ 線形回帰: データを直線(1次式)で予測しようとします。
例えば特徴量の数が1つのときは\(y=ax+b\)、
特徴量が3つのときは \(y = a_0 + a_1x_1 + a_2x_2+a_3x_3\) という関数で予測します。
・多項式回帰: データを曲線(多項式)で予測しようとします。例えば特徴量が1つ、次数を3とすると\(y=a_0 + a_1x + a_2x^2 + a_3x^3\) という関数で予測します。
ここで、発想を転換してみましょう。\(x, x^2, x^3\) をそれぞれ 別の変数 と考えてみてください。例えば、
\(x \to x_1\)
\(x^2 \to x_2\)
\(x^3 \to x_3\)
と置き換えると、多項式回帰の式は \(y = a_0 + a_1x_1 + a_2x_2 + a_3x_3\) となります。これ、特徴量の数が3つ\((x1, x2, x3)\)のときの線形回帰の形と同じになっています。
つまり特徴量(\(x\)のべき乗)を新たな特徴量として考えれば多項式回帰も線形回帰として扱えるんです!
それではモデルの学習をします。説明変数にはX_poly、目的変数にはyを使います。
# モデルの学習
reg = LinearRegression()
reg.fit(X_poly, y)これで多項式回帰が実行されました。
STEP.5 結果をグラフで表示
それでは最後に下のグラフを作成しましょう。
# 回帰曲線用データの作成
X_val = np.linspace(0,12, 100)
X_val = X_val.reshape(-1,1)
# 回帰曲線用データに対して 1, x, x^2, x^3 という 4 列の特徴量を作成する
X_poly_val = polynomial_features.fit_transform(X_val)
# 回帰曲線用データに対する予測
y_pred = reg.predict(X_poly_val)
# グラフを作成(figsizeでサイズを決める)
plt.figure(figsize=(8,3))
# 実測値(青点)をプロット
plt.scatter(X, y)
# 予測値(赤線)を表示
plt.plot(X_val,y_pred,c="red")
# y座標の上限と下限を設定
plt.ylim([0,70])
# x座標のラベルを設定
plt.xlabel("month")
# y座標のラベルを設定
plt.ylabel("sales")
# グラフを表示
plt.show()2行目 で回帰曲線を表示するためのデータを作ります。np.linspaceは指定した範囲を等間隔に区切った配列を作ります。今回は0~12の範囲を100等分したデータを作成しました。
例えば100の所を13にすると[0, 1, … ,11,12]という配列ができます。イメージ的には100個のデータそれぞれに対して多項式回帰による予測値を求めてそれを折れ線グラフで表示すると言う感じです。そのため100をもっと小さい数字に変えると赤線はカクカクになるはずです。
3行目 では先ほどと同じようにこれら100個のデータに対して「.reshape(-1,1)」をして2次元配列にします。
6行目 でも先ほどと同じようにPolynomialFeaturesで3次までの特徴量を生成します。
9行目 では未知のデータ(今回は100個のデータ)に対して予測をしています。予測を行いたい場合は「.predict(目的変数)」を使えばできます。今回は予測したデータにy_predと名付けました。
plt.figure以降は普通のグラフ作成と同じなので説明は省略します。
上のコードを実行すると下のような図が作成されます。
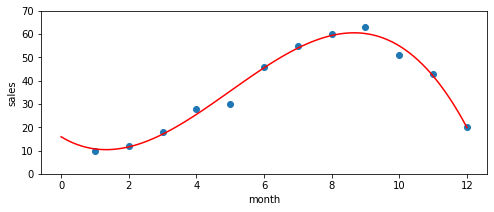
青点が実際のデータで、赤い曲線が多項式回帰による予測結果を表しています。これを見ると3次の多項式でいい感じに予測できていることが分かります。
過学習ってなに?
さきほど多項式回帰は直線じゃ表せないデータに対して予測できると話しました。確かに次数を増やすことによってより予測が正確になります。
例えば下のグラフは今回使ったデータに対して線形回帰を適用した結果です。
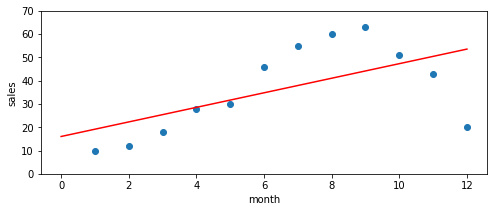
たしかにこれでは上手に予測ができてるとは言えなさそうですよね。
ここまでの話を聞いて、じゃあ次数をもっと増やせばよいんじゃないかと感じた人もいるかと思います。今回はdegreeを3にしましたが、これを10とか20とかにした方がもっと予測精度が高くなるんじゃないかと思うかもしれません。
ということでdegreeを大きくして多項式回帰をやってみましょう。下の図はdegreeが3,5,10,20の4パターンについて多項式回帰を実施した結果です。


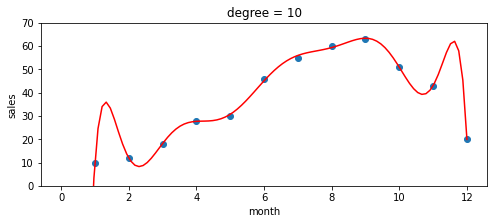

何やら様子がおかしいですね。degreeが3、5のときはよく予測できていますが、10と20のときはぐにゃぐにゃになってしまっています。どうやらdegreeは大きければ良いというものでもなさそうですね。
このことを過学習と言います!
degreeが10と20の場合を見てください。これらは予測モデルとしては適していないものの、青点はちゃんと通っていますね。つまりすでに与えられたデータ(青点)に対してのみ学習しすぎた結果、未知のデータに対する予測(赤線)がうまくいかなくなっているんです。これが過学習です。
過学習を抑えるには自由度(degreeのこと)を調整したり正則化項を追加したりすることが考えられます。
おわりに
いかがでしたでしょうか。
今回の記事ではpythonを使って多項式分析について説明していきました。こんな感じでプログラミングを使えばいろいろなことができます。非常に興味深いですよね。
データの数値をいじるとまた違う結果が得られるので興味がある人はぜひやってみてください!またこの記事では非線形回帰分析の中でも多項式分析について説明しました。他にも色々な手法があるので是非調べてやってみてください!
これからもこのようにプログラミングで色々やっていきたいと思います。ぼくが一番勉強になるので続けていきたいです!
最後までこの記事を読んでくれてありがとうございました。
この記事が役に立ったら幸いです。

