こんにちは!しゅんです!
今回は主成分分析を使ってNBAのポジションによって差が出るスタッツを調べます!
NBAには5つのポジションが存在しますが、ポジションによって結構役割が異なります。それでは一体ポジションによって何が違うのでしょうか?今回はそれを主成分分析を使って調べていきたいと思います。
この記事では下の動画で説明した分析をプログラミングでどうやるか解説しています!
ぜひこちらの動画も見てみてください!
それでは解説していきましょう!
普段はNBAのデータ分析をしたりしています。
ぜひこちらの記事も読んでみてください!
このブログでは経営工学を勉強している現役理系大学生が、経営工学に関することを色々話していきます!
ぼくが経営工学を勉強している中で感じたことや、興味深かったことを皆さんと共有出来たら良いなと思っています。
そもそも経営工学とは何なのでしょうか。Wikipediaによると
経営工学(けいえいこうがく、英: engineering management)は、人・材料・装置・情報・エネルギーを総合したシステムの設計・改善・確立に関する活動である。そのシステムから得られる結果を明示し、予測し、評価するために、工学的な分析・設計の原理・方法とともに、数学、物理および社会科学の専門知識と経験を利用する。
引用元 : 経営工学 – Wikipedia
長々と書いてありますが、要は経営、経済の課題を理系的な観点から解決する学問です。
主成分分析ってなに?
まずは主成分分析について解説していきたいと思います。
ザックリ説明すると主成分分析は
重要な情報をピックアップする分析
です。
例えばNBAには得点数、アシスト数。3P%など様々なスタッツがあります。それでは一体これらのスタッツのうち、どの項目がチームの勝敗に影響するでしょうか。
すぐに見つけるのは難しそうですよね。それはなぜならデータの数が多いからです。
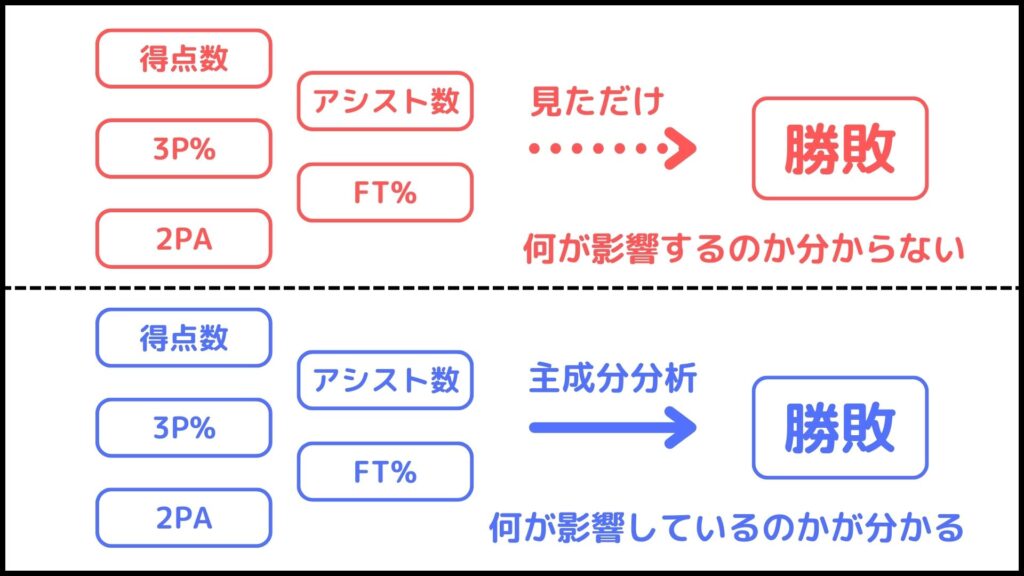
主成分分析ではこのような問題を解決するための1つの手法です。主成分分析はいわゆる多変量解析の一つで、膨大な量の情報から重要な情報をピックアップする分析です。
今回の例でいえばたくさんのスタッツ項目がある中で、勝敗に影響を与える項目をピックアップすることができます。
より詳しく言うと、各主成分はそれぞれの項目の線形結合で表されます。そして係数をみることでどの項目が重要かを調べることができます。この係数のことをウェイト(重み)と言ったりします。
それでは実際にNBAのデータを使って主成分分析をやってみましょう!
データを手に入れる
今回は1987-1988シーズンと2021-2022シーズンの2つのデータを使いたいと思います。今と昔でポジションの役割が変わっているかもしれないのでこれらを比較していきます。
データの前処理はこちらの記事と同じなのでこれを参考にしてください。

それでは分析に入っていきましょう!
主成分分析をpythonでやってみる
ポジションはG, F, Cの3種類にして分析をしていきたいと思います。また、データの前処理の時点でpandas, numpy, matplotlibはインポートされていることとします。
以下の手順で分析を進めてみたいと思います。
複数の変数を扱うのでスケールを合わせます
寄与率、ウェイトなどを調べます
スクリープロットを使って求めます
ちゃんと分析出来ているか図示してみます
どの項目が主成分に影響を与えているかを見ましょう
それでは1つずつ解説していきます。
STEP. 1 データの標準化
主成分分析は複数の変数を扱う分析です。そのため基本的には分析の前にデータを標準化する必要があります。
簡単に言うと単位を合わせるのが標準化です。例えば身長と体重は単位が違うのでそのまま比較することができません。そういう場合に標準化を使うことで身長と体重を比較することが出来ます。
より詳しく説明すると、標準化は平均0、標準偏差1になるようにデータを変形することを言います。
詳しくははこちらの記事で説明しているのでぜひ読んでみてください!

まずはデータを標準化をするデータ(説明変数)とポジションデータ(目的変数)の2つに分けましょう。なお、ジョーダンの記事と同様に42試合以上出場した選手のみのデータ、df_42を扱います。
# 目的変数と説明変数の分割
X = df_42[["3P%", "2P%", "FT%", "TRB", "AST", "STL", "BLK", "TOV", "PF", "PTS"]] # 説明変数
y = df_42["Pos"] # 目的変数df_42の中から主成分分析に用いるスタッツ項目だけを抽出してXに格納しました。またyにはポジションデータを入れました。
この時点でyはPG, SG, SF, PF, Cのいずれかが入っているはずです。5つだと数が多すぎるのでPG, SGをG, SF, PFをFとしてG, F, Cの3つのポジションについて考えましょう。
y.replace(["PG", "SG"], "G", inplace=True) # PGとSGをGにする
y.replace(["SF", "PF"], "F", inplace=True) # SFとPFをFにする
pythonで標準化をするためにはscikit-learnのStandardScalerを使うので、まずはインポートしましょう。
# 標準化をするために必要なものをインポート
from sklearn.preprocessing import StandardScalerそれでは説明変数Xを標準化していきます。
# データの標準化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)この時点で標準化が完了しました。
STEP. 2 主成分分析の実行
主成分分析を実行するためにはscikit-learnのPCAをインポートする必要があります。
# 主成分分析をするのに必要なものをインポート
from sklearn.decomposition import PCAそれでは実際に主成分分析を実行しくんですが、ここで1つ重要な問題があります。それは主成分を何個にするかです。
これは主成分の寄与率を見ることによって判断できます。詳しくはSTEP. 3で判断するので、今はとりあえず主成分を10個にして分析してみましょう。
# 主成分分析の実行
pca = PCA(n_components=10) # n_componentsで主成分の数を決める
X_pca = pca.fit_transform(X_scaled)ということで主成分分析ができました。
STEP. 3 最適な主成分の数を求める
ということで次に最適な主成分の数を求めましょう。第1、第2主成分とかだと大事な情報が手に入るんですけど、第10主成分とかになるとほとんど役に立たなかったりします。そしてそれを判断する指標が寄与率になります。
まずはそれぞれの主成分の寄与率を見てみましょう。
# 結果の確認
print(pca.explained_variance_ratio_) # 寄与率の確認
左上から順に第1,2,3,…主成分の寄与率となっています。
寄与率というのは、その主成分がどれだけデータ全体を説明できているかを表すもので、大きければ大きい程うまく説明できているということを示しています。
主成分は寄与率が大きい順に第1、第2と振り分けられ、最後の方になると寄与率はほぼ0です。ということで最後の方はほとんどデータを説明できてないということになります。
それでは一体何個まで主成分を採用すれば良いのでしょうか。これを解決する1つの目安がスクリープロットです。
説明の前にまずはスクリープロットを描いてみましょう。
# グラフのサイズを指定
plt.figure(figsize = (10,6))
# 横軸を1~10を1刻みにする
x = [i for i in range(1,11)]
# 横軸が主成分の番号、縦軸寄与率の折れ線グラフを作成
plt.plot(x,pca.explained_variance_ratio_, marker = "o")
# x座標の目盛りを1刻みにする
plt.xticks(range(1,11,1))
# グラフを表示
plt.show()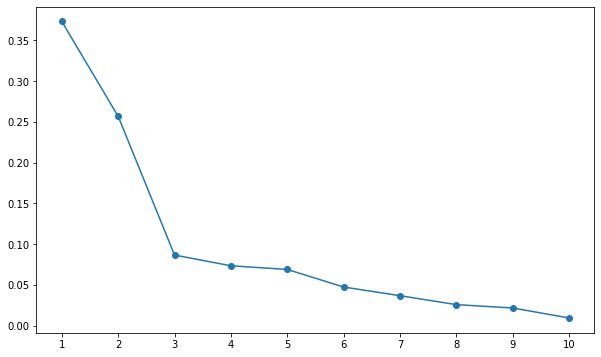
こんな感じでスクリープロットが描けました。横軸が主成分の番号、縦軸がその主成分の寄与率を表しています。これを見ると第3主成分以降の寄与率がゆるやかに減少していますね。言い換えると第3主成分以降はあまり役に立たないということです。
ということで一度第3主成分までを採用しましょう。
このようにスクリープロットで急激に減少が緩やかになるところまでを文性に用いる手法をエルボー法と言います。詳しくは下の記事で解説しているのでぜひ読んでみてください!

STEP. 4 グラフの表示
それでは第1~第3主成分までを使ってグラフを描いてみましょう。
## 主成分スコアを使って3通りの散布図を作成
# ポジションごとに色分けするための準備
pos = df_42["Pos"].unique() # PosにG, F, Cを保存
colors = ["blue", "green", "red"] #ポジションごとの色を指定
# 第1主成分と第2主成分を使った散布図の作成
fig = plt.figure(figsize=(20, 5)) # グラフの大きさを設定
ax1 = fig.add_subplot(131) # グラフの場所を設定
for i, p in enumerate(pos):
ax1.scatter(X_pca[df_42["Pos"] == p, 0], X_pca[df_42["Pos"] == p, 1],
color=colors[i], label=p, alpha=0.5, s=100) # ポジションごとに色分けして散布図を作成
ax1.set_xlabel("PC1") # x軸のラベルを設定
ax1.set_ylabel("PC2") # y軸のラベルを設定
ax1.set_title("PC1 × PC2") # タイトルを設定
ax1.legend() # ポジションのラベルを表示
# 第2主成分と第3主成分を使った散布図の作成(第1×第2のときとほぼ同じ)
ax2 = fig.add_subplot(132) # グラフの場所を設定
for i, p in enumerate(pos):
ax2.scatter(X_pca[df_42["Pos"] == p, 1], X_pca[df_42["Pos"] == p, 2],
color=colors[i], label=p, alpha=0.5, s=100)
ax2.set_xlabel("PC2")
ax2.set_ylabel("PC3")
ax2.set_title("PC2 × PC3")
ax2.legend()
# 第3主成分と第1主成分を使った散布図の作成(第1×第2のときとほぼ同じ)
ax3 = fig.add_subplot(133) # グラフの場所を設定
for i, p in enumerate(pos):
ax3.scatter(X_pca[df_42["Pos"] == p, 2], X_pca[df_42["Pos"] == p, 0],
color=colors[i], label=p, alpha=0.5, s=100)
ax3.set_xlabel("PC3")
ax3.set_ylabel("PC1")
ax3.set_title("PC3 × PC1")
ax3.legend()
# 散布図を表示
plt.show()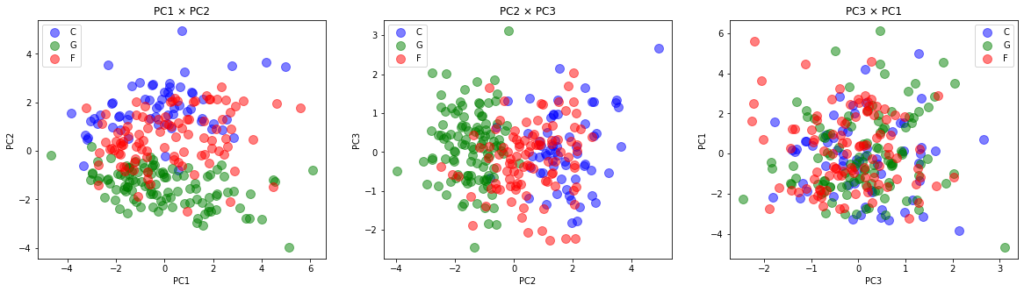
コードがめちゃくちゃ長くなっているように見えますが、主成分を入れ替えてほぼ同じことを3回繰り返しているだけなので、実質最初の「第1主成分と第2主成分を使った散布図の作成」の所まで書いて、あとはコピペでやれば良いと思います。
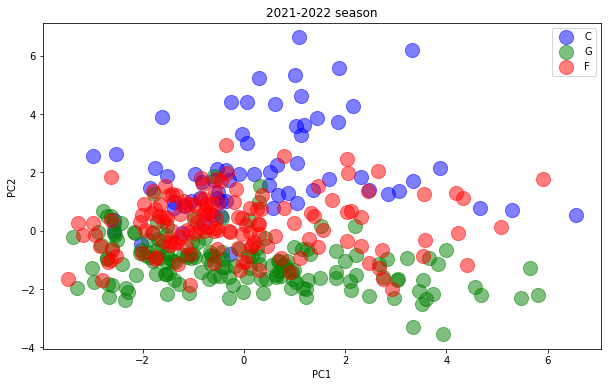
ということでそれぞれの主成分を使った散布図ができました。これを見ると、第2主成分が最もポジション間の違いを表しているように見えますね。
左と真ん中の散布図を見るとPC2が大きいとCになり、PC2が小さいとGになり、その中間がFになることが読み取れます。一方で右の図を見ると、PC1とPC3だけでは3つのポジションの違いをあまり表現できていなさそうです。
ということでここからはPC2の中身を見ていくのが良さそうですね。
STEP. 5 主成分の構成要素を見る
ということで第2主成分を見たいので、一度主成分の数を2にして分析し直します。
# 主成分分析の実行
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)主成分が何で構成されているかを見るにはpca.components_でできます。分かりやすくするために第2主成分に影響を与えている項目順にソートしましょう。どれだけ影響を与えているかをウェイトと呼び、ウェイトの絶対値が大きい順に並べます。
# 第二主成分のウェイトを取得
weights = pd.DataFrame(pca.components_, columns=X.columns).iloc[1]
# 第二主成分のウェイトが大きい順にソート
sorted_weights = weights.abs().sort_values(ascending=False)
# ソートした結果を用いて、説明変数を並び替えたデータフレームを作成
sorted_df = pd.DataFrame(pca.components_, columns=X.columns)[sorted_weights.index]
# sorted_dfを表示
print(sorted_df)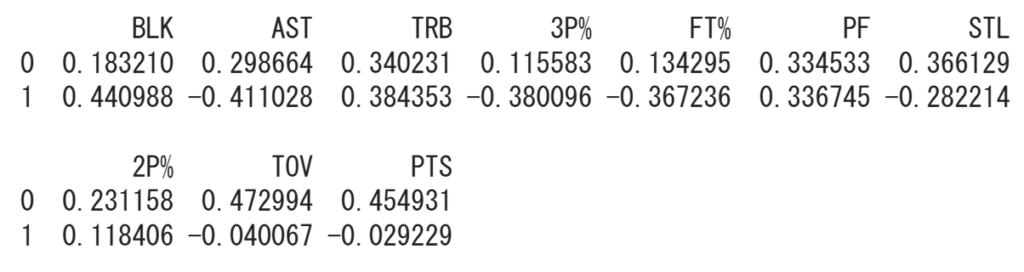
pca.components_には第1主成分と第2主成分のウェイトが入っており、今回は第2主成分の情報が欲しいので.iloc[1]で第2主成分の情報のみを抜き取りweightsに保管します。
注意:pythonの配列は基本0から始まります。そのため2番目を指定したい場合は1, 10番目を指定したい場合は9というように1個前の数字を使う必要があります。
そして次に.sorted_valuesでウェイトが大きい順に並べ替えします。マイナスの数字も含んでいるので、absを付けて絶対値で評価します。
最後に大きい順に並べ替えたデータをデータフレーム形式に整えます。
そしてそれを表示すると上の図のようになりました。一番上からスタッツ項目、第1主成分のウェイト、第2主成分のウェイトと並んでいます。そのため今回は各項目と一番下の数字を照らし合わせればよいということです。
ここからは第2主成分のウェイトについて話していきます。
ウェイトの見方は、例えばBLKのウェイトが最も大きな正の値を取っており、これはBLKの値によってポジションが区別されやすく、BLKの値が大きい程C、小さい程Gになりやすいと言うことを表しています。
反対にASTのウェイトは二番目に大きな負の値を取っており、これはASTの値によってポジションが区別されやすく、ASTの値が大きい程G、小さい程Cになりやすいということを表しています。
どうでしょうか、どちらも直観と正しいように思えます。
このように主成分分析を使うことによってポジションによって差が出やすいスタッツを調べることができます。
現代NBAと比較してみる
最後に2021-2022シーズンでも同様の分析を行い、昔と今でポジションによって差が出やすいスタッツはどう変化したのかを見ていきたいと思います。
やり方は1987-1988シーズンと変わらないのでコードは省略します。
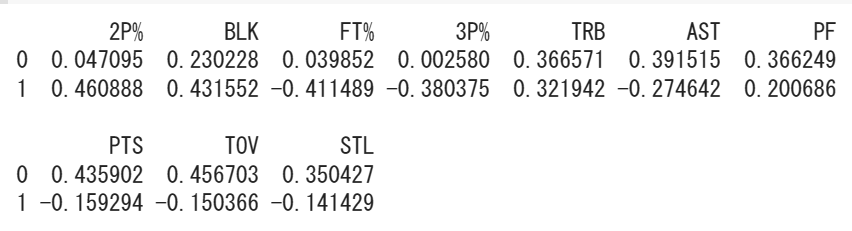
このような結果になりました。散布図を見るとやはり第2主成分を見た方が良さそうなので、ウェイトも第2主成分のものが大きい順にソートしました。
見比べてみると、ウェイトが大きく変わっているのは2P%とASTですかね。2P%は1987-1988シーズンでは0.11なのに対し、2021-2022シーズンでは0.46と最も値を取っています。つまり1987-1988シーズンと比べて、2021-2022シーズンにおける2P%の値はポジションで差が出やすくなったということを表しています。
逆にASTは値が大きく下がっていますね。これは1987-1988シーズンに比べて2021-2022シーズンにおけるASTの値はポジション間で差が出にくくなったということを表しています。
なぜこのような結果が起きたのでしょうか。例えばASTに関しては、昔と比べてFやCの選手がパスするようになったと言う仮説が挙げられます。例えば二コラヨキッチという選手はCにもかかわらず平均7.9アシストを記録しリーグ8位に輝いています。他にも5アシスト以上残したG以外の選手がちらほらいます。
ただこれらの情報からG以外の選手のASTが増えたと結論付けるのはまだ早いです。
ここからさらに、例えば今と昔のポジションごとのASTの平均値などを比べたりする必要がありそうです。
2P%はなんででしょうね…昔はCも2Pを結構外してたのか、それとも今のCがめちゃめちゃ2Pを確率よく決めているのか、はたまた今はGは3Pを打つようになってあまり2Pを打たなくなった結果2P%が下がったのか…色々考察できる余地はありそうです。
今回は主成分分析がメインなのでここで終わりですが、興味がある方はここらへんを分析してみると面白そうですね!
おわりに
いかがでしたでしょうか。
今回の記事ではpythonを使って主成分分析について説明していきました。こんな感じでプログラミングを使えばいろいろなことができます。非常に興味深いですよね。
違うデータを使うととまた違う結果が得られるので興味がある人はぜひやってみてください!またその先の分析もぜひやってみてください!
これからもこのようにプログラミングで色々やっていきたいと思います。ぼくが一番勉強になるので続けていきたいです!
最後までこの記事を読んでくれてありがとうございました。
この記事が役に立ったら幸いです。